本系列共有三篇:
.NET Core 中的日志与分布式链路追踪
分布式链路追踪框架的基本实现原理(当前)
开源一个简单的兼容 Jaeger 的框架
柠檬(Lemon丶)大佬在一月份开业了柠檬研究院,研究院指导成员学习分布式和云原生技术,本月课题是分布式链路追踪,学习 Dapper 论文、Jaeger 的使用,以及完成一个兼容 Jaeger 的链路追踪框架。
笔者将作业分为三部分,一篇文章加上实现代码,本文是第二篇。
分布式追踪
什么是分布式追踪
分布式系统
当我们使用 Google 或者 百度搜索时,查询服务会将关键字分发到多台查询服务器,每台服务器在自己的索引范围内进行搜索,搜索引擎可以在短时间内获得大量准确的搜索结果;同时,根据关键字,广告子系统会推送合适的相关广告,还会从竞价排名子系统获得网站权重。通常一个搜索可能需要成千上万台服务器参与,需要经过许多不同的系统提供服务。
多台计算机通过网络组成了一个庞大的系统,这个系统即是分布式系统。
在微服务或者云原生开发中,一般认为分布式系统是通过各种中间件/服务网格连接的,这些中间件提供了共享资源、功能(API等)、文件等,使得整个网络可以当作一台计算机进行工作。
分布式追踪
在分布式系统中,用户的一个请求会被分发到多个子系统中,被不同的服务处理,最后将结果返回给用户。用户发出请求和获得结果这段时间是一个请求周期。
当我们购物时,只需要一个很简单的过程:
获取优惠劵 -> 下单 -> 付款 -> 等待收货然而在后台系统中,每一个环节都需要经过多个子系统进行协作,并且有严格的流程。例如在下单时,需要检查是否有优惠卷、优惠劵能不能用于当前商品、当前订单是否符合使用优惠劵条件等。
下图是一个用户请求后,系统处理请求的流程。
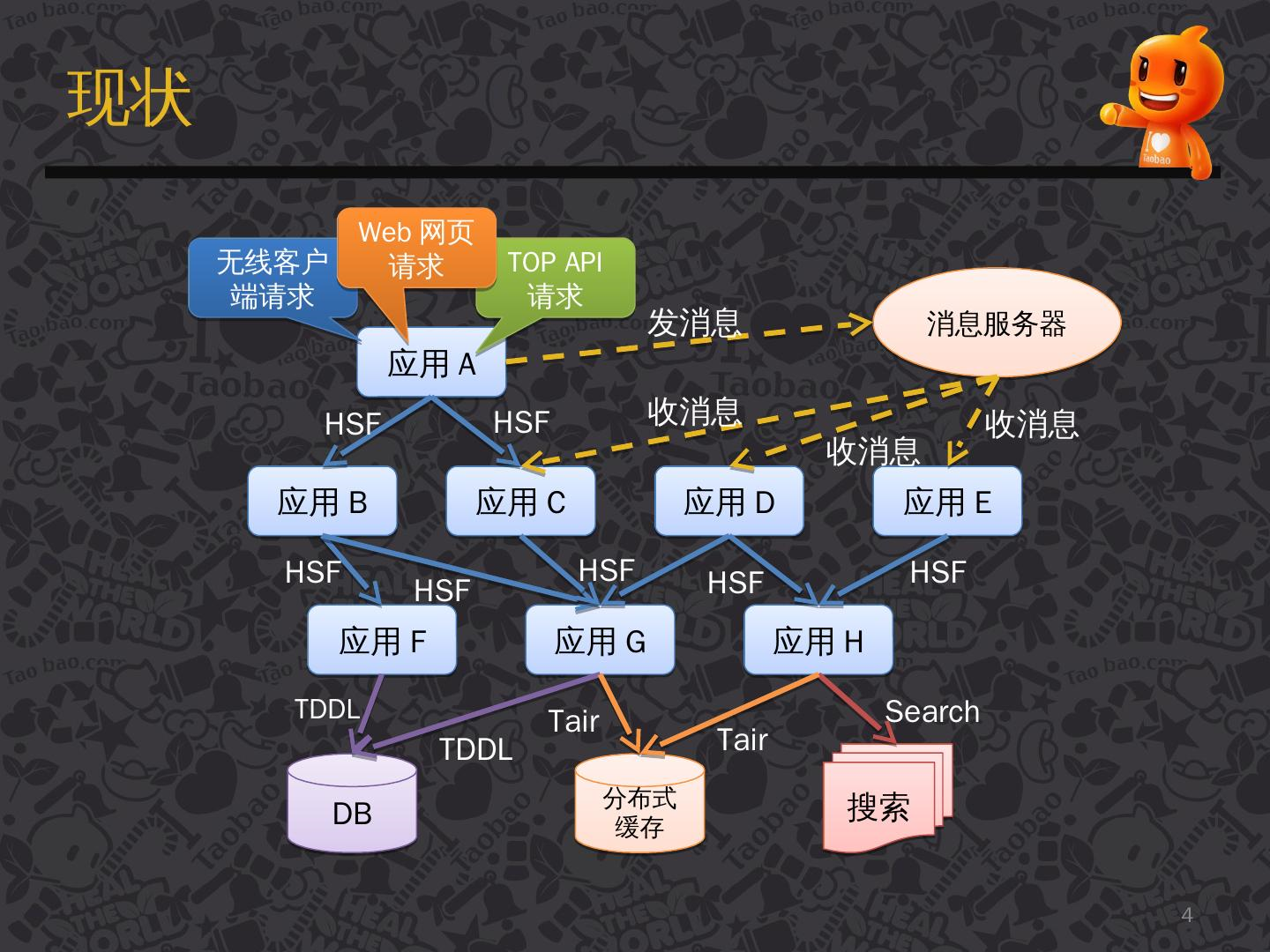
【图片来源:鹰眼下的淘宝分布式调用跟踪系统介绍】
图中出现了很多箭头,这些箭头指向了下一步要流经的服务/子系统,这些箭头组成了链路网络。
在一个复杂的分布式系统中,任何子系统出现性能不佳的情况,都会影响整个请求周期。根据上图,我们设想:
1.系统中有可能每天都在增加新服务或删除旧服务,也可能进行升级,当系统出现错误,我们如何定位问题?
2.当用户请求时,响应缓慢,怎么定位问题?
3.服务可能由不同的编程语言开发,1、2 定位问题的方式,是否适合所有编程语言?
分布式追踪有什么用呢
随着微服务和云原生开发的兴起,越来越多应用基于分布式进行开发,但是大型应用拆分为微服务后,服务之间的依赖和调用变得越来越复杂,这些服务是不同团队、使用不同语言开发的,部署在不同机器上,他们之间提供的接口可能不同(gRPC、Restful api等)。
为了维护这些服务,软件领域出现了 Observability 思想,在这个思想中,对微服务的维护分为三个部分:
- 度量(
Metrics):用于监控和报警; - 分布式追踪(Tracing):用于记录系统中所有的跟踪信息;
- 日志(Logging):记录每个服务只能中离散的信息;
这三部分并不是独立开来的,例如 Metrics 可以监控 Tracing 、Logging 服务是否正常运行。Tacing 和 Metrics 服务在运行过程中会产生日志。
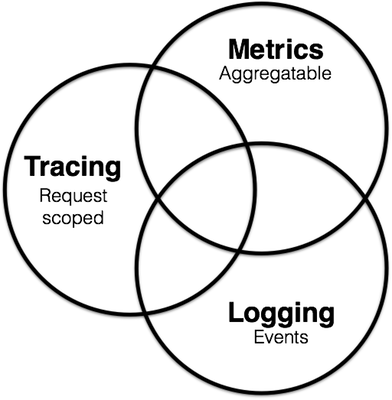
深入了解请戳爆你的屏幕:https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
近年来,出现了 APM 系统,APM 称为 应用程序性能管理系统,可以进行 软件性能监视和性能分析。APM 是一种 Metrics,但是现在有融合 Tracing 的趋势。
回归正题,分布式追踪系统(Tracing)有什么用呢?这里可以以 Jaeger 举例,它可以:
- 分布式跟踪信息传递
- 分布式事务监控
- 服务依赖性分析
- 展示跨进程调用链
- 定位问题
- 性能优化
Jaeger 需要结合后端进行结果分析,jaeger 有个 Jaeger UI,但是功能并不多,因此还需要依赖 Metrics 框架从结果呈现中可视化,以及自定义监控、告警规则,所以很自然 Metrics 可能会把 Tracing 的事情也做了。
Dapper
Dapper 是 Google 内部使用的分布式链路追踪系统,并没有开源,但是 Google 发布了一篇 《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》 论文,这篇论文讲述了分布式链路追踪的理论和 Dapper 的设计思想。
有很多链路追踪系统是基于 Dapper 论文的,例如淘宝的鹰眼、Twitter 的 Zipkin、Uber 开源的 Jaeger,分布式链路追踪标准 OpenTracing 等。
论文地址:
https://static.googleusercontent.com/media/research.google.com/en//archive/papers/dapper-2010-1.pdf
译文:
http://bigbully.github.io/Dapper-translation/
不能访问 github.io 的话,可以 clone 仓库去看 https://github.com/bigbully/Dapper-translation/tree/gh-pages
Dapper 用户接口:
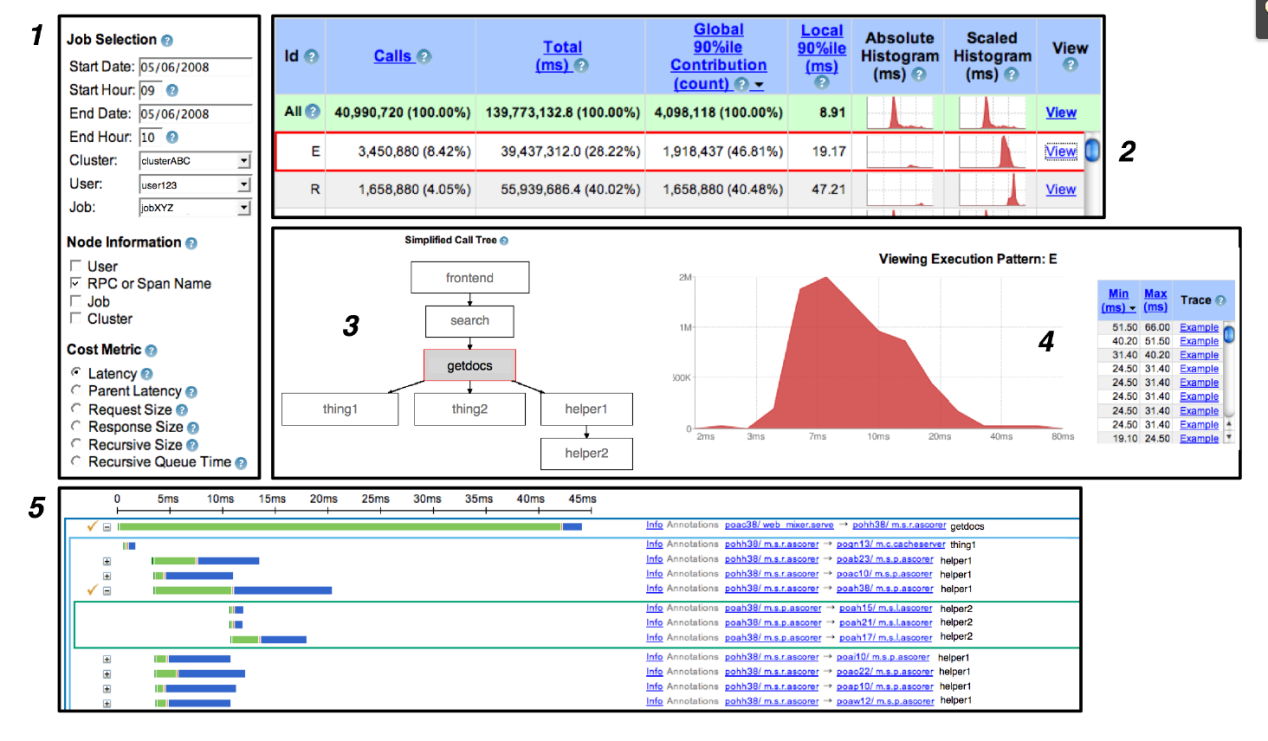
分布式追踪系统的实现
下图是一个由用户 X 请求发起的,穿过多个服务的分布式系统,A、B、C、D、E 表示不同的子系统或处理过程。
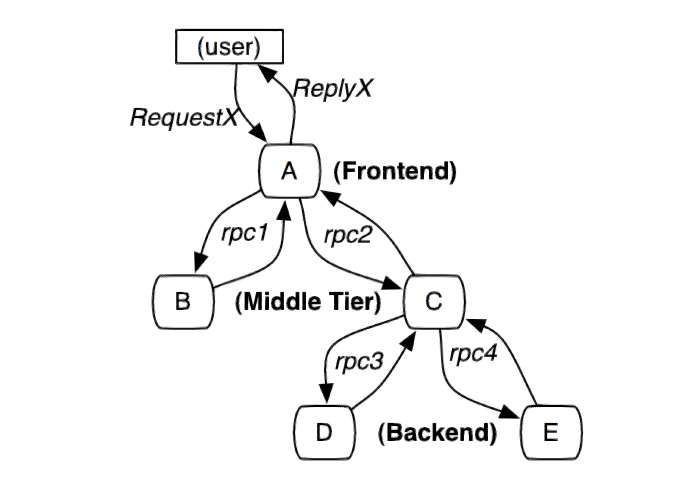
在这个图中, A 是前端,B、C 是中间层、D、E 是 C 的后端。这些子系统通过 rpc 协议连接,例如 gRPC。
一个简单实用的分布式链路追踪系统的实现,就是对服务器上每一次请求以及响应收集跟踪标识符(message identifiers)和时间戳(timestamped events)。
分布式服务的跟踪系统需要记录在一次特定的请求后系统中完成的所有工作的信息。用户请求可以是并行的,同一时间可能有大量的动作要处理,一个请求也会经过系统中的多个服务,系统中时时刻刻都在产生各种跟踪信息,必须将一个请求在不同服务中产生的追踪信息关联起来。
为了将所有记录条目与一个给定的发起者X关联上并记录所有信息,现在有两种解决方案,黑盒(black-box)和基于标注(annotation-based)的监控方案。
黑盒方案:
假定需要跟踪的除了上述信息之外没有额外的信息,这样使用统计回归技术来推断两者之间的关系。
基于标注的方案:
依赖于应用程序或中间件明确地标记一个全局ID,从而连接每一条记录和发起者的请求。
优缺点:
虽然黑盒方案比标注方案更轻便,他们需要更多的数据,以获得足够的精度,因为他们依赖于统计推论。基于标注的方案最主要的缺点是,很明显,需要代码植入。在我们的生产环境中,因为所有的应用程序都使用相同的线程模型,控制流和 RPC 系统,我们发现,可以把代码植入限制在一个很小的通用组件库中,从而实现了监测系统的应用对开发人员是有效地透明。
Dapper 基于标注的方案,接下来我们将介绍 Dapper 中的一些概念知识。
跟踪树和 span
从形式上看,Dapper 跟踪模型使用的是树形结构,Span 以及 Annotation。
在前面的图片中,我们可以看到,整个请求网络是一个树形结构,用户请求是树的根节点。在 Dapper 的跟踪树结构中,树节点是整个架构的基本单元。
span 称为跨度,一个节点在收到请求以及完成请求的过程是一个 span,span 记录了在这个过程中产生的各种信息。每个节点处理每个请求时都会生成一个独一无二的的 span id,当 A -> C -> D 时,多个连续的 span 会产生父子关系,那么一个 span 除了保存自己的 span id,也需要关联父、子 span id。生成 span id 必须是高性能的,并且能够明确表示时间顺序,这点在后面介绍 Jaeger 时会介绍。
Annotation 译为注释,在一个 span 中,可以为 span 添加更多的跟踪细节,这些额外的信息可以帮助我们监控系统的行为或者帮助调试问题。Annotation 可以添加任意内容。
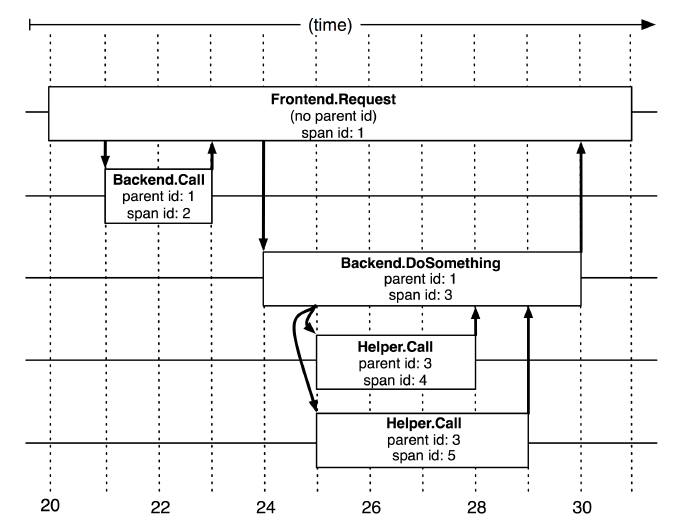
到此为止,简单介绍了一些分布式追踪以及 Dapper 的知识,但是这些不足以严谨的说明分布式追踪的知识和概念,建议读者有空时阅读 Dapper 论文。
要实现 Dapper,还需要代码埋点、采样、跟踪收集等,这里就不再细谈了,后面会介绍到,读者也可以看看论文。
Jaeger 和 OpenTracing
OpenTracing
OpenTracing 是与分布式系统无关的API和用于分布式跟踪的工具,它不仅提供了统一标准的 API,还致力于各种工具,帮助开发者或服务提供者开发程序。
OpenTracing 为标准 API 提供了接入 SDK,支持这些语言:Go, JavaScript, Java, Python, Ruby, PHP, Objective-C, C++, C#。
当然,我们也可以自行根据通讯协议,自己封装 SDK。
读者可以参考 OpenTracing 文档:https://opentracing.io/docs/
接下来我们要一点点弄清楚 OpenTracing 中的一些概念和知识点。由于 jaeger 是 OpenTracing 最好的实现,因此后面讲 Jaeger 就是 Opentracing ,不需要将两者严格区分。
Jaeger 结构
首先是 JAEGER 部分,这部分是代码埋点等流程,在分布式系统中处理,当一个跟踪完成后,通过 jaeger-agent 将数据推送到 jaeger-collector。jaeger-collector 负责处理四面八方推送来的跟踪信息,然后存储到后端,可以存储到 ES、数据库等。Jaeger-UI 可以将让用户在界面上看到这些被分析出来的跟踪信息。
OpenTracing API 被封装成编程语言的 SDK(jaeger-client),例如在 C# 中是 .dll ,Java 是 .jar,应用程序代码通过调用 API 实现代码埋点。
jaeger-Agent 是一个监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector。
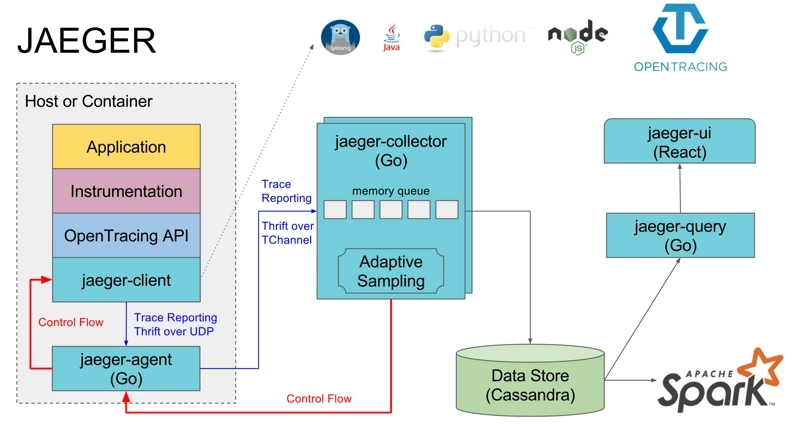
【图片来源:https://segmentfault.com/a/1190000011636957】
OpenTracing 数据模型
在 OpenTracing 中,跟踪信息被分为 Trace、Span 两个核心,它们按照一定的结构存储跟踪信息,所以它们是 OpenTracing 中数据模型的核心。
Trace 是一次完整的跟踪,Trace 由多个 Span 组成。下图是一个 Trace 示例,由 8 个 Span 组成。
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C is a `ChildOf` Span A)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G `FollowsFrom` Span F)Tracing:
a Trace can be thought of as a directed acyclic graph (DAG) of Spans。
有点难翻译,大概意思是 Trace 是多个 Span 组成的有向非循环图。
在上面的示例中,一个 Trace 经过了 8 个服务,A -> C -> F -> G 是有严格顺序的,但是从时间上来看,B 、C 是可以并行的。为了准确表示这些 Span 在时间上的关系,我们可以用下图表示:
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
[Span A···················································]
[Span B··············································]
[Span D··········································]
[Span C········································]
[Span E·······] [Span F··] [Span G··] [Span H··]有个要注意的地方, 并不是 A -> C -> F 表示 A 执行结束,然后 C 开始执行,而是 A 执行过程中,依赖 C,而 C 依赖 F。因此,当 A 依赖 C 的过程完成后,最终回到 A 继续执行。所以上图中 A 的跨度最大。
Span 格式
要深入学习,就必须先了解 Span,请读者认真对照下面的图片和 Json:
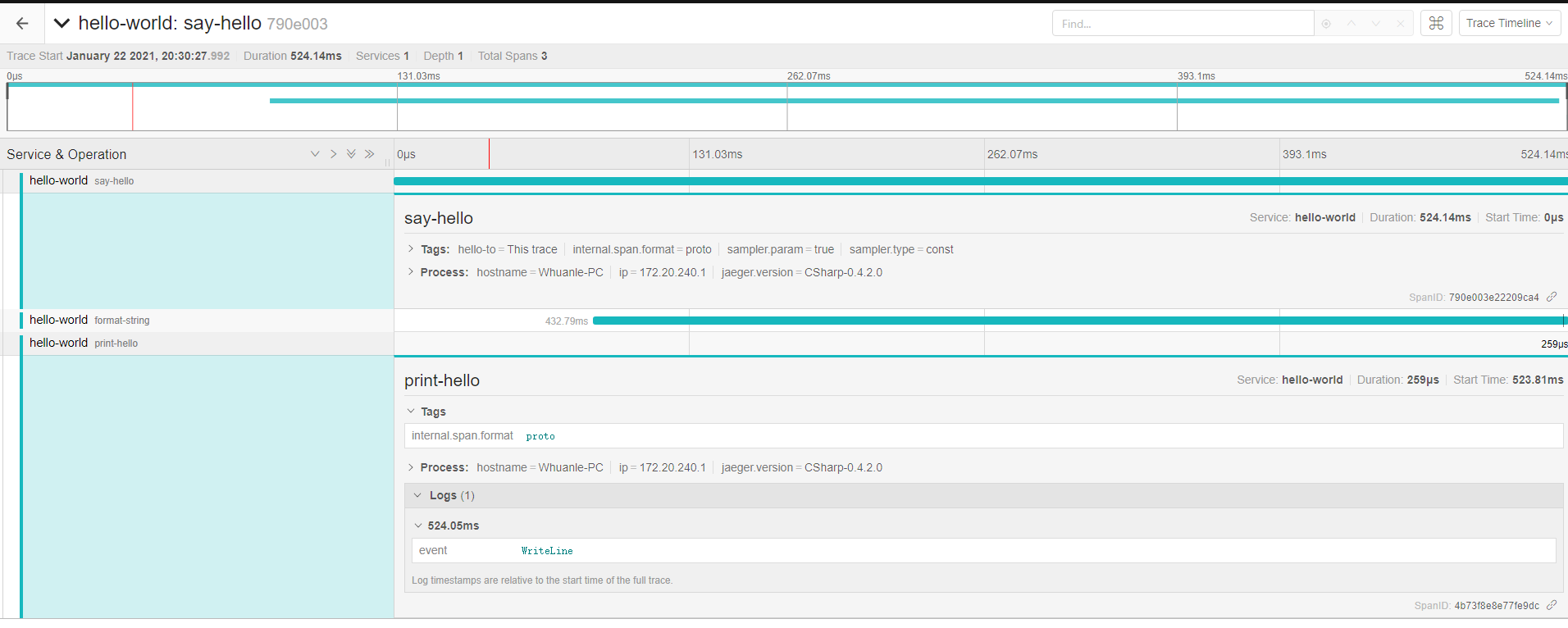
json 地址: https://github.com/whuanle/DistributedTracing/issues/1
后续将围绕这张图片和 Json 来举例讲述 Span 相关知识。
Trace
一个简化的 Trace 如下:
注:不同编程语言的字段名称有所差异,gRPC 和 Restful API 的格式也有所差异。
"traceID": "790e003e22209ca4",
"spans":[...],
"processes":{...}前面说到,在 OpenTracing 中,Trace 是一个有向非循环图,那么 Trace 必定有且只有一个起点。
这个起点会创建一个 Trace 对象,这个对象一开始初始化了 trace id 和 process,trace id 是一个 32 个长度的字符串组成,它是一个时间戳,而 process 是起点进程所在主机的信息。
下面笔者来说一些一下 trace id 是怎么生成的。trace id 是 32个字符串组成,而实际上只使用了 16 个,因此,下面请以 16 个字符长度去理解这个过程。
首先获取当前时间戳,例如获得 1611467737781059 共 16 个数字,单位是微秒,表示时间 2021-01-24 13:55:37,秒以下的单位这里就不给出了,明白表示时间就行。
在 C# 中,将当前时间转为这种时间戳的代码:
public static long ToTimestamp(DateTime dateTime)
{
DateTime dt1970 = new DateTime(1970, 1, 1, 0, 0, 0, 0);
return (dateTime.Ticks - dt1970.Ticks)/10;
}
// 结果:1611467737781059如果我们直接使用 Guid 生成或者 string 存储,都会消耗一些性能和内存,而使用 long,刚刚好可以表示时间戳,还可以节约内存。
获得这个时间戳后,要传输到 Jaeger Collector,要转为 byet 数据,为什么要这样不太清楚,按照要求传输就是了。
将 long 转为一个 byte 数组:
var bytes = BitConverter.GetBytes(time);
// 大小端
if (BitConverter.IsLittleEndian)
{
Array.Reverse(bytes);
}long 占 8 个字节,每个 byte 值如下:
0x00 0x05 0xb9 0x9f 0x12 0x13 0xd3 0x43然后传输到 Jaeger Collector 中,那么获得的是一串二进制,怎么表示为字符串的 trace id?
可以先还原成 long,然后将 long 输出为 16 进制的字符串:
转为字符串(这是C#):
Console.WriteLine(time.ToString("x016"));结果:
0005b99f1213d343Span id 也是这样转的,每个 id 因为与时间戳相关,所以在时间上是唯一的,生成的字符串也是唯一的。
这就是 trace 中的 trace id 了,而 trace process 是发起请求的机器的信息,用 Key-Value 的形式存储信息,其格式如下:
{
"key": "hostname",
"type": "string",
"value": "Your-PC"
},
{
"key": "ip",
"type": "string",
"value": "172.6.6.6"
},
{
"key": "jaeger.version",
"type": "string",
"value": "CSharp-0.4.2.0"
}Ttace 中的 trace id 和 process 这里说完了,接下来说 trace 的 span。
Span
Span 由以下信息组成:
- An operation name:操作名称,必有;
- A start timestamp:开始时间戳,必有;
- A finish timestamp:结束时间戳,必有;
- Span Tags.:Key-Value 形式表示请求的标签,可选;
- Span Logs:Key-Value 形式表示,记录简单的、结构化的日志,必须是字符串类型,可选;
- SpanContext :跨度上下文,在不同的 span 中传递,建立关系;
- References t:引用的其它 Span;
span 之间如果是父子关系,则可以使用 SpanContext 绑定这种关系。父子关系有 ChildOf、FollowsFrom 两种表示,ChildOf 表示 父 Span 在一定程度上依赖子 Span,而 FollowsFrom 表示父 Span 完全不依赖其子Span 的结果。
一个 Span 的简化信息如下(不用理会字段名称大小写):
{
"traceID": "790e003e22209ca4",
"spanID": "4b73f8e8e77fe9dc",
"flags": 1,
"operationName": "print-hello",
"references": [],
"startTime": 1611318628515966,
"duration": 259,
"tags": [
{
"key": "internal.span.format",
"type": "string",
"value": "proto"
}
],
"logs": [
{
"timestamp": 1611318628516206,
"fields": [
{
"key": "event",
"type": "string",
"value": "WriteLine"
}
]
}
]
}OpenTracing API
在 OpenTracing API 中,有三个主要对象:
- Tracer
- Span
- SpanContext
Tracer可以创建Spans并了解如何跨流程边界对它们的元数据进行Inject(序列化)和Extract(反序列化)。它具有以下功能:
- 开始一个新的
Span Inject一个SpanContext到一个载体Extract一个SpanContext从载体
由起点进程创建一个 Tracer,然后启动进程发起请求,每个动作产生一个 Span,如果有父子关系,Tracer 可以将它们关联起来。当请求完成后, Tracer 将跟踪信息推送到 Jaeger-Collector中。
详细请查阅文档:https://opentracing.io/docs/overview/tracers/
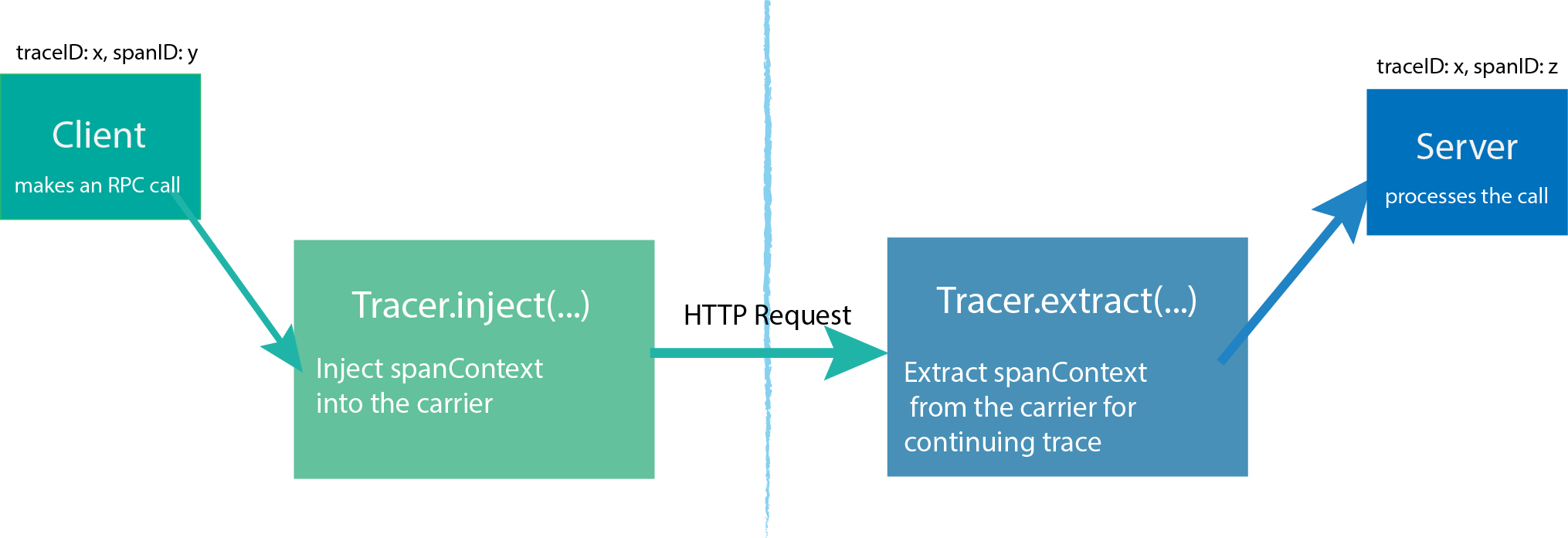
SpanContext 是在不同的 Span 中传递信息的,SpanContext 包含了简单的 Trace id、Span id 等信息。
我们继续以下图作为示例讲解。
A 创建一个 Tracer,然后创建一个 Span,代表自己 (A),再创建两个 Span,分别代表 B、C,然后通过 SpanContext 传递一些信息到 B、C;B 和 C 收到 A 的消息后,也创建一个 Tracer ,用来 Tracer.extract(...) ;其中 B 没有后续,可以直接返回结果;而 C 的 Tracer 继续创建两个 Span,往 D、E 传递 SpanContext。
这个过程比较复杂,笔者讲不好,建议读者参与 OpenTracing 的官方文档。
详细的 OpenTracing API,可以通过编程语言编写相应服务时,去学习各种 API 的使用。
.NET Core 笔者写了一篇,读者有兴趣可以阅读:【.NET Core 中的日志与分布式链路追踪】https://www.cnblogs.com/whuanle/p/14256858.html

文章评论
一条来自微信小程序的评论