机器性能
本次测试所用服务器硬件配置如下,此机器除了 Mysql 和 StartRocks 还部署了其它很多 Docker 服务。
CPU:
AMD Ryzen™ 7 8745H w/ Radeon™ 780M Graphics × 16内存:
DDR5 5600 MT/S 32G(16G*2)磁盘性能:
Timing cached reads: 64174 MB in 1.99 seconds = 32256.62 MB/sec
Timing buffered disk reads: 3562 MB in 3.00 seconds = 1186.39 MB/sec初始化数据库环境
Mysql:
CREATE TABLE <code>users</code> (
<code>id</code> bigint(20) unsigned NOT NULL AUTO_INCREMENT,
<code>username</code> varchar(32) NOT NULL,
<code>phone</code> char(11) NOT NULL,
<code>email</code> varchar(64) NOT NULL,
<code>gender</code> tinyint(3) unsigned NOT NULL DEFAULT 0 COMMENT '0未知 1男 2女',
<code>age</code> tinyint(3) unsigned NOT NULL DEFAULT 0,
<code>status</code> tinyint(3) unsigned NOT NULL DEFAULT 1 COMMENT '1正常 2禁用 3注销',
<code>province_id</code> smallint(5) unsigned NOT NULL DEFAULT 0,
<code>city_id</code> mediumint(8) unsigned NOT NULL DEFAULT 0,
<code>register_source</code> tinyint(3) unsigned NOT NULL DEFAULT 1 COMMENT '1web 2ios 3android 4api',
<code>score</code> int(10) unsigned NOT NULL DEFAULT 0,
<code>created_at</code> datetime NOT NULL,
<code>updated_at</code> datetime NOT NULL,
<code>last_login_at</code> datetime DEFAULT NULL,
PRIMARY KEY (<code>id</code>),
UNIQUE KEY <code>uk_phone</code> (<code>phone</code>),
KEY <code>idx_status_created_id</code> (<code>status</code>,<code>created_at</code>,<code>id</code>),
KEY <code>idx_created_at_id</code> (<code>created_at</code>,<code>id</code>),
KEY <code>idx_email</code> (<code>email</code>),
KEY <code>users_created_at_index</code> (<code>created_at</code>)
) ENGINE=InnoDB AUTO_INCREMENT=935300001 DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMICStarRocks:
CREATE TABLE <code>users</code> (
<code>id</code> bigint NOT NULL COMMENT "",
<code>created_at</code> datetime NOT NULL COMMENT "",
<code>username</code> varchar(32) NOT NULL COMMENT "",
<code>phone</code> varchar(11) NOT NULL COMMENT "",
<code>email</code> varchar(64) NOT NULL COMMENT "",
<code>gender</code> tinyint NOT NULL DEFAULT "0" COMMENT "",
<code>age</code> tinyint NOT NULL DEFAULT "0" COMMENT "",
<code>status</code> tinyint NOT NULL DEFAULT "1" COMMENT "",
<code>province_id</code> smallint NOT NULL DEFAULT "0" COMMENT "",
<code>city_id</code> int NOT NULL DEFAULT "0" COMMENT "",
<code>register_source</code> tinyint NOT NULL DEFAULT "1" COMMENT "",
<code>score</code> int NOT NULL DEFAULT "0" COMMENT "",
<code>updated_at</code> datetime NOT NULL COMMENT "",
<code>last_login_at</code> datetime NULL COMMENT ""
)
ENGINE=OLAP
PRIMARY KEY(<code>id</code>, <code>created_at</code>)
PARTITION BY RANGE(<code>created_at</code>) (
START ("2020-01-01") END ("2026-12-31") EVERY (INTERVAL 1 MONTH)
)
DISTRIBUTED BY HASH(<code>id</code>) BUCKETS 8
PROPERTIES (
"replication_num" = "1"
);Python 写入数据的脚本:
from concurrent.futures import ThreadPoolExecutor, as_completed
from datetime import datetime, timedelta
import pymysql
HOST = "192.168.1.1"
PORT = 3306 // 或 9030
USER = "root"
PASSWORD = "123456"
DATABASE = "testdata"
START_ID = 1
TOTAL_ROWS = 500_000_000
WORKERS = 8
BATCH_SIZE = 10_000
BASE_TIME = datetime(2024, 1, 1, 0, 0, 0)
INSERT_SQL = """
INSERT INTO users (
id, username, phone, email, gender, age, status,
province_id, city_id, register_source, score,
created_at, updated_at, last_login_at
) VALUES (
%s, %s, %s, %s, %s, %s, %s,
%s, %s, %s, %s,
%s, %s, %s
)
"""
def make_conn():
return pymysql.connect(
host=HOST,
port=PORT,
user=USER,
password=PASSWORD,
database=DATABASE,
charset="utf8mb4",
autocommit=False,
read_timeout=300,
write_timeout=300,
connect_timeout=30,
)
def build_rows(start_id: int, end_id: int):
rows = []
for n in range(start_id, end_id):
created_at = BASE_TIME + timedelta(seconds=n % 31_536_000)
updated_at = created_at
last_login_at = created_at + timedelta(days=n % 30)
rows.append((
n,
f"user_{n}",
f"1{n:010d}",
f"user_{n}@test.local",
n % 3,
18 + (n % 43),
2 if n % 20 == 0 else 1,
(n % 34) + 1,
(n % 340) + 1,
(n % 4) + 1,
n % 100000,
created_at.strftime("%Y-%m-%d %H:%M:%S"),
updated_at.strftime("%Y-%m-%d %H:%M:%S"),
last_login_at.strftime("%Y-%m-%d %H:%M:%S"),
))
return rows
def worker(worker_no: int, start_id: int, end_id: int):
conn = make_conn()
inserted = 0
try:
with conn.cursor() as cur:
current = start_id
while current <= end_id:
next_id = min(current + BATCH_SIZE, end_id + 1)
rows = build_rows(current, next_id)
cur.executemany(INSERT_SQL, rows)
conn.commit()
inserted += len(rows)
current = next_id
if inserted % 100000 == 0 or current > end_id:
print(f"worker={worker_no} inserted={inserted} range={start_id}-{end_id}")
finally:
conn.close()
def split_ranges(start_id: int, total_rows: int, workers: int):
base = total_rows // workers
remain = total_rows % workers
current = start_id
result = []
for i in range(workers):
size = base + (1 if i < remain else 0)
s = current
e = current + size - 1
result.append((i + 1, s, e))
current = e + 1
return result
def main():
ranges = split_ranges(START_ID, TOTAL_ROWS, WORKERS)
print("ranges:", ranges)
with ThreadPoolExecutor(max_workers=WORKERS) as pool:
futures = [pool.submit(worker, worker_no, s, e) for worker_no, s, e in ranges]
for future in as_completed(futures):
future.result()
print("done")
if __name__ == "__main__":
main()5亿条数据到底占多大空间
本次测试中,MySQL实际写入数据量为4.6亿条(因测试过程中未完成5亿条写入),StarRocks按计划写入5亿条数据,以下为两者的存储占用详情。
对于 Mysql:
8.0K ./testdata/users.frm
136G ./testdata/users.ibd
4.0K ./testdata/db.opt
136G ./testdataStarRocks 是 256G。
Mysql 表里面创建了比较多的索引,通过以下 SQL 可以获取表的索引以及索引数据占用的空间:
SELECT
TABLE_NAME AS 表名,
CONCAT(ROUND((INDEX_LENGTH / 1024 / 1024), 2), ' MB') AS 索引大小,
CONCAT(ROUND((DATA_LENGTH / 1024 / 1024), 2), ' MB') AS 数据大小,
CONCAT(ROUND(((INDEX_LENGTH + DATA_LENGTH) / 1024 / 1024), 2), ' MB') AS 总大小
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = 'testdata'
AND TABLE_NAME = 'users';| 指标 | 数值 | 换算 |
|---|---|---|
| 索引大小 | 79943.56 MB | ≈ 78.07 GB |
| 数据大小 | 51887.00 MB | ≈ 50.67 GB |
| 总大小 | 131830.56 MB | ≈ 128.74 GB |

笔者这台机器部署了很多服务,所以实际上日常运行 Mysql、StarRocks 两个数据库应该不需要 10G 内存。
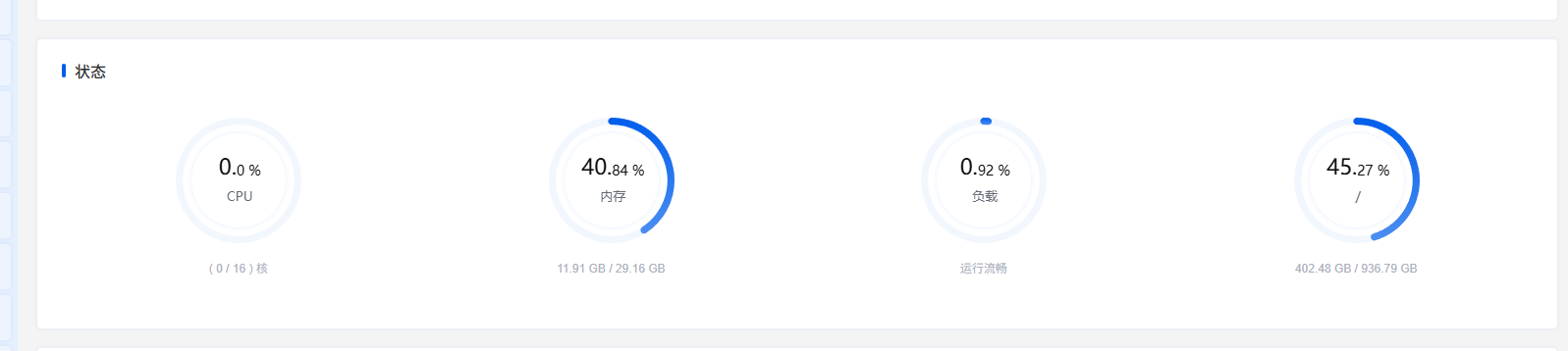
统计数据量
大数据量下,全表数据量统计(select count(*))是业务中常见场景,以下为MySQL与StarRocks的性能对比,每组测试重复3次,取平均值以减少偶然误差。
select count(*) from users;在 Mysql 里面,统计数据量是大坑,需要 1-2 分钟。
[2026-04-11 14:21:22] 在 1 m 11 s 165 ms (execution: 1 m 11 s 153 ms, fetching: 12 ms) 内检索到从 1 开始的 1 行StarRocks 只需要 260ms。
[2026-04-11 14:20:29] 在 261 ms (execution: 254 ms, fetching: 7 ms) 内检索到从 1 开始的 1 行所以对在业务系统中统计数据量是非常麻烦的一个事情,如果只是需要知道全表数据量,有很多方法可以做,例如单独设计数据量统计表、Redis 记录数据量等,但是往往页面显示数据量时需要分页、搜索、筛选,会导致在大数据量下耗时非常长。
因此在大数量时读写分离很有必要,统计数据量、分页查询大小、join 条件等通过 StarRocks 来操作。
有索引会多块
数据库本身已有以下索引:
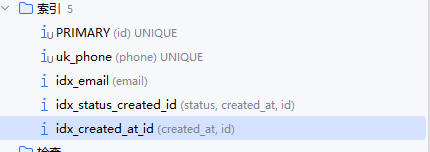
一开始 AI 给我生成表的时候,我在想为什么有的索引只包含字段,有的列把 id 也包进去了,查了资料发现 InnoDB 二级索引默认含主键,所以实际上 (created_at,id) 跟 (created_at) 是一样的,但是在排序方面有区别,因为索引的数据是会排序的。
以下场景显式定义 (col, id) 有明显收益:
- 查询包含
ORDER BY col, id; - 查询需要按
col分页(如WHERE col > x ORDER BY col, id LIMIT n),id可用于稳定分页顺序; col的区分度很低(如大量重复值),加上id可提高索引的 “区分度”,优化索引查找效率。
回归正题,在使用主键的情况下,Mysql 读取 1000 条数据:
select *
from users
where id in (...);[2026-04-12 08:52:56] 在 113 ms (execution: 79 ms, fetching: 34 ms) 内检索到从 1 开始的 64 行所以在表数据量非常大时,完全可以在 StarRocks 执行一些查询操作,最终获取一份数据 id 后在 Mysql 业务数据库查询数据做业务处理。
对于手机号这种字符串字段,如果做了索引,其实各种查询操作也不会慢的。
select *
from users
where phone like '1000%'
order by phone desc
limit 100 offset 10;
select *
from users
where phone like '%1000%'
order by phone desc
limit 100 offset 10;Mysql:
[2026-04-11 14:23:05] 在 48 ms (execution: 13 ms, fetching: 35 ms) 内检索到从 1 开始的 100 行
[2026-04-12 09:11:44] 在 375 ms (execution: 347 ms, fetching: 28 ms) 内检索到从 1 开始的 100 行StarRocks:
[2026-04-12 09:08:09] 在 576 ms (execution: 546 ms, fetching: 30 ms) 内检索到从 1 开始的 100 行
[2026-04-12 09:11:36] 在 822 ms (execution: 789 ms, fetching: 33 ms) 内检索到从 1 开始的 100 行上面的测验可以说明几个问题。
对于字符串,走前缀区配时, like 'xxx%' 性能性能也会非常好,4.6 亿数据执行时间只需要 13ms。
只有前缀匹配 like 'xxx%',才能真正利用索引做范围扫描(range)B + 树可以直接定位到前缀匹配的起始位置,只扫描符合范围的索引节点,所以 %xxx% 这种走不了索引会导致全盘扫描,导致 MySQL 执行耗时从 13ms 暴涨到 347ms,性能下降了 26 倍。
不过对于 StarRocks,StarRocks 是 OLAP 引擎,默认的前缀索引对like '%x%'完全无效,所以查询都会比 Mysql 慢。
对于字符串等场景,如果设计的查询方案可以走索引,那么即使数据量很大,其实也不需要担心查询时间。
优化筛选查询
单是用户表,在业务需求中往往需要对手机号、用户名、邮箱等进行模糊查询,like %xxx% 这种情况必然会出现,我们不可能让产品经理改需求,但是无论在 Mysql 还是 StarRocks 使用 like %xxx% 在大数据量时耗时都会变大,所以我们需要找到一种方式,既可以满足产品对于订单、用户表等多个动态字段模糊搜索,又要让查询速度变快。
select *
from users
where phone like '%1000%' or email like '%user_10%' or username like '%user_11%'
order by phone desc
limit 100 offset 100;Mysql:
[2026-04-12 09:31:37] 在 912 ms (execution: 880 ms, fetching: 32 ms) 内检索到从 1 开始的 100 行StarRocks:
[2026-04-12 09:32:24] 在 1 s 588 ms (execution: 1 s 557 ms, fetching: 31 ms) 内检索到从 1 开始的 100 行StarRocks/Doris 支持 ngram 分词倒排索引,原理和 ES 类似,但直接集成在数仓引擎中,避免了数据同步的麻烦,适合分析场景。但是经过笔者测试,where phone like '%1000%' or email like '%user_10%' or username like '%user_11%' 走不了索引,查询速度也好慢。
无论是 Mysql 还是 StarRocks 在多条件模糊查询时,由于索引机制,都会导致查询速度缓慢,最后只能使用 ElasticSearch 做模糊查询,ElasticSearch 这方面非常强。
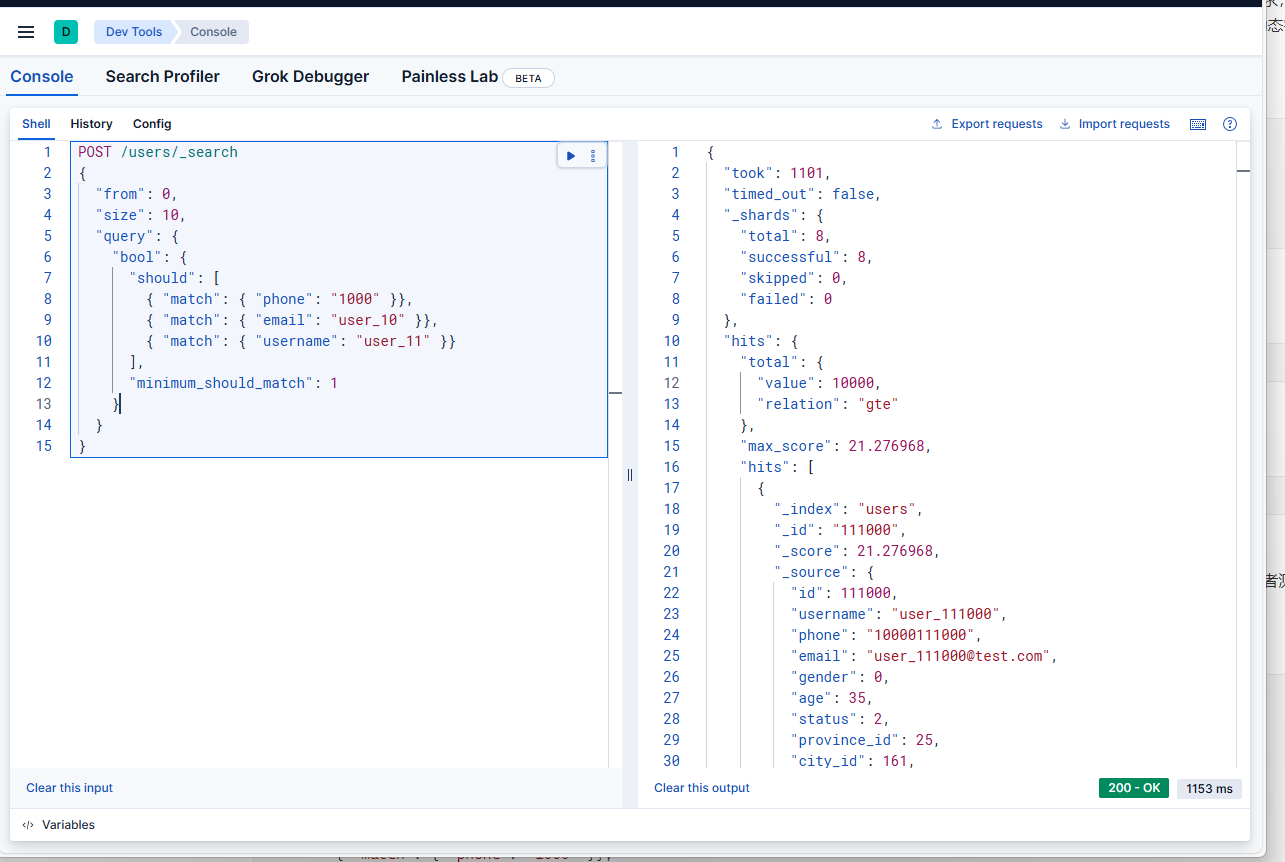
POST /users/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"should": [
{ "match": { "phone": "1000" }},
{ "match": { "email": "user_10" }},
{ "match": { "username": "user_11" }}
],
"minimum_should_match": 1
}
}
}
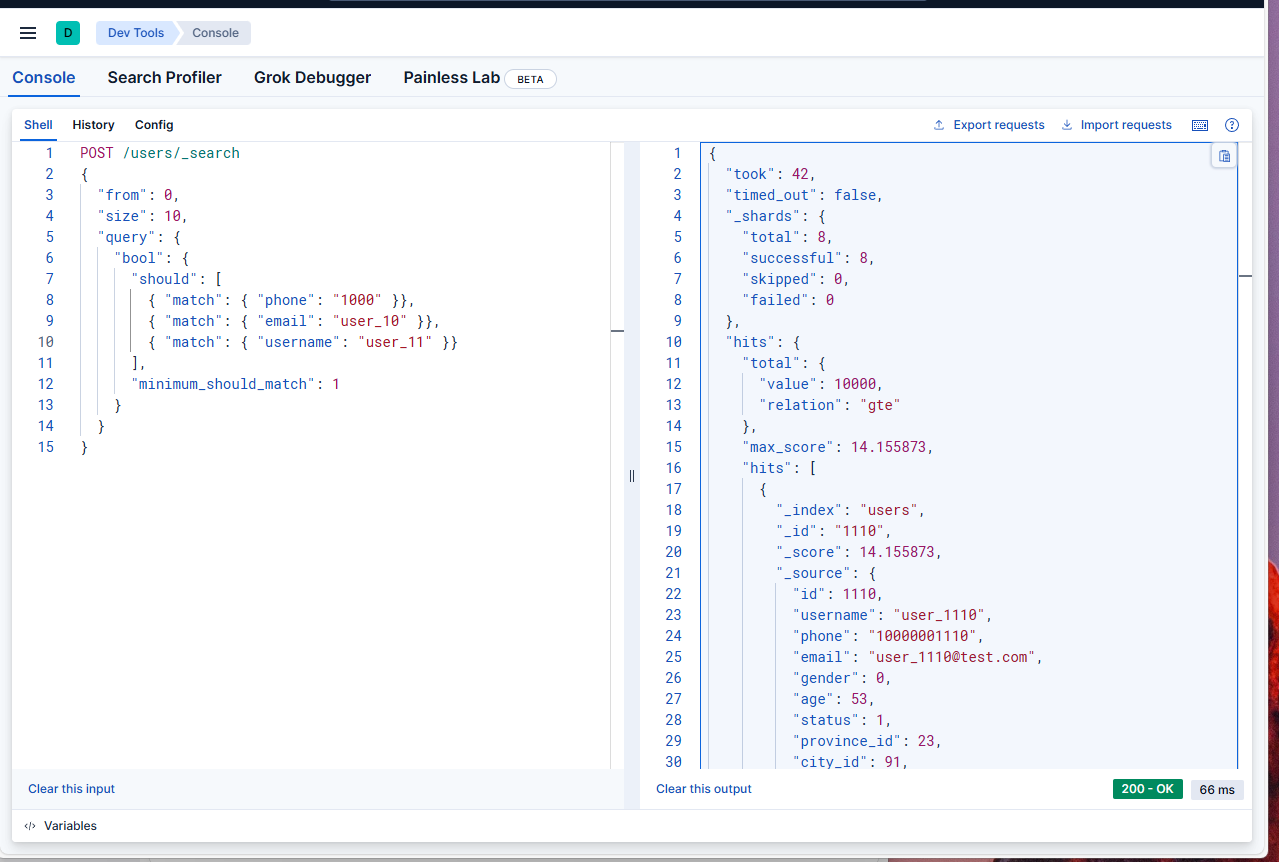
一个查询只能使用一个索引
在 Mysql 的 users 表中,我们给很多字段设置了索引,包括创建时间 idx_created_at_id。
PRIMARY KEY (<code>id</code>),
UNIQUE KEY <code>uk_phone</code> (<code>phone</code>),
KEY <code>idx_status_created_id</code> (<code>status</code>,<code>created_at</code>,<code>id</code>),
KEY <code>idx_created_at_id</code> (<code>created_at</code>,<code>id</code>),
KEY <code>idx_email</code> (<code>email</code>)如果我们按时间来排查范围,有 idx_created_at_id 的加持,下面的 SQL 执行速度会不会非常快?
select *
from users
where phone like '1000%'
and created_at > '2024-04-25 17:46:20'
order by phone desc
limit 100 offset 10;然而实际测试,Mysql:
[2026-04-11 11:55:19] 在 24 s 86 ms (execution: 24 s 66 ms, fetching: 20 ms) 内检索到从 1 开始的 9 行StarRocks:
在 19 s 578 ms (execution: 19 s 561 ms, fetching: 17 ms) 内检索到 0 行但是我不是给 phone、create_at 都创建索引了嘛,为什么还会这么慢?先看执行计划。

确实有两个索引:
uk_phone(phone)idx_created_at_id(created_at, id)
但问题是 MySQL 通常只能选一个 “最有用” 的索引,然后回表过滤其他条件。所以在前面的查询中,MySQL 必须二选一:
- 若选择
uk_phone(实际执行计划):可快速定位phone LIKE '1000%'的2000多万行数据,但该索引不包含created_at字段,需逐行回表校验created_at条件,回表次数过多导致性能下降; - 若选择
idx_created_at_id:可快速定位created_at > '2024-04-25'的2.3亿行数据,但该索引不包含phone字段,需逐行回表校验phone条件,扫描行数更多,性能更差;
所以对于 and 条件来说,即使每个列都添加了索引,但是一个查询里面只能使用一个索引。
资料出处:https://dev.mysql.com/doc/refman/8.4/en/optimizing-innodb-queries.html
对于 or 条件,倒是宽松一些,可能会走索引合并,但是大部分情况跟 and 差不多。
| 逻辑操作 | 索引使用特点 | 常见问题 | 最佳优化方案 |
|---|---|---|---|
AND |
通常只选一个索引,其他条件靠回表 | 回表次数太多(如你的 2000 万次) | 复合索引(把 AND 的列都放进去) |
OR |
可能触发 “索引合并”,但限制多 | 范围查询时索引失效,导致全表扫描 | 改写成 UNION,让每个分支用各自的索引 |
另外,索引的列位置也非常重要,下面举例说明。
基于 where phone like '1000%' and created_at > '2024-04-25 17:46:20',我们可以创建一个联合索引,把两个字段放在一个索引。
CREATE INDEX idx_phone_created ON users (phone, created_at);执行这个命令重建索引花费了 17 分钟。
但是执行这个 SQL ,执行查询还是需要 20s,还是那个索引导致右侧 create_at 失效。
SELECT *
FROM users FORCE INDEX (idx_phone_created)
WHERE phone LIKE '1000%'
AND created_at > '2024-04-25 17:46:20'
ORDER BY phone DESC
LIMIT 100 OFFSET 10;但是如果你这样创建索引,最终需要 238030341 行扫描。
-- 新建索引:(created_at, phone)
CREATE INDEX idx_created_phone ON users (created_at, phone);因为 LIKE '1000%' 只需要扫两千多万行,而 created_at > '2024-04-25 17:46:20' 满足的情况实在太多了,需要扫描 2.3 亿行,会导致查询时间需要几分钟!
所以做 where 查询时,需要将数据量少的限制条件放在前面,并且这个可以走索引,后面的条件可能走不了索引,会导致查询速度变慢。
并且 where 时最好不要使用 like %xxx 这种条件,否则联合索引失效!
使用 StarRocks BitMap 优化选项筛选
users 表有以下字段:
gender(0/1/2 → 仅 3 种)
status(1/2/3 → 仅 3 种)
register_source(1/2/3/4 → 仅 4 种)
province_id(省级 ID,全国≈34 → 低基数)
city_id(市级 ID,几百~几千 → 标准低基数)
在业务项目里面,表里面往往会有枚举表示数据的状态,但是这些数据在 Mysql 里面做索引会非常吃亏,因为基数低,重复率巨高,而 Mysql 默认索引是 B-tree
B-tree 索引适合高基数的数据如 user_id/phone/订单号、范围查询和数据排序,碰到这种只有集中可能的数据,使用索引会非常吃亏。
例如按照地区和注册信息条件筛选用户时:
SELECT COUNT(*) FROM users
WHERE
status = 1
AND gender = 1
AND register_source = 3
AND province_id = 11;这个语句查询了 4 分钟还没有查完。
在 StarRocks 里面添加 BitMap 索引。
-- 给 users 表创建 Bitmap 索引
ALTER TABLE users ADD INDEX idx_bitmap_gender (gender) USING BITMAP;
ALTER TABLE users ADD INDEX idx_bitmap_status (status) USING BITMAP;
ALTER TABLE users ADD INDEX idx_bitmap_register_source (register_source) USING BITMAP;
ALTER TABLE users ADD INDEX idx_bitmap_province_id (province_id) USING BITMAP;
ALTER TABLE users ADD INDEX idx_bitmap_city_id (city_id) USING BITMAP;执行查询:
[2026-04-12 12:56:58] 在 116 ms (execution: 92 ms, fetching: 24 ms) 内检索到从 1 开始的 1 行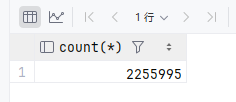
大数据分页做法
在业务项目中往往需要对数据分页返回给用户,前端传递 pageNo、pageSize,但是在数据量大时,使用 where 之后再做 offset、limit 会吃掉很多性能。随着数据量达到百万、千万级别,传统 offset 分页会因为需要扫描并跳过大量数据而急剧变慢,甚至导致数据库压力过高。
为此,我们采用Token 游标分页方案,完全抛弃传统的页码与偏移量模式,只通过连续游标实现高性能滚动分页。
Token 游标分页不支持任意页码跳转,只能顺序翻页。
分页方式
第一次请求:允许前端传入 pageNo 和 pageSize,用于自定义跳转到任意起始页。
后端根据 pageNo 和 pageSize 计算出起始位置对应的最后一条数据 ID,并生成第一个 Token。
后续翻页:只需要传递上一页返回的 Token,不再需要 pageNo、offset,保持高性能。
全程依然使用 where id > ? 高性能查询,兼顾跳页需求与大数据性能。
自定义起始页(第一次请求)
- 前端传:
pageNo=100、pageSize=20(想直接从第 100 页开始) - 后端计算:
offset = (pageNo - 1) * pageSize - 后端查询:
order by id limit offset, pageSize - 拿到当前页数据 + 最后一条数据的 id
- 生成 token,把这个 id 存入 Redis
- 返回:数据 + nextPageToken
后续所有页(只传 token)
- 前端只传:
pageToken=xxx - 后端从 Redis 取出游标 id
- 查询:
where id > 游标id order by id limit pageSize - 生成新 token、返回新数据 + 新 token
- 不再需要任何 pageNo、offset
C# 代码示例:
/// <summary>
/// 分页请求(第一次可传PageNo自定义起始页,后续只传Token)
/// </summary>
public class PageRequest
{
/// <summary>
/// 分页Token(第一次不传,传PageNo;后续只传这个)
/// </summary>
public string? PageToken { get; set; }
/// <summary>
/// 页码(仅第一次请求允许传,用于自定义起始页)
/// </summary>
public int PageNo { get; set; } = 1;
/// <summary>
/// 每页条数(10-100)
/// </summary>
public int PageSize { get; set; } = 20;
}
// ======================
// 情况1:传了 Token → 走游标分页
// ======================
if (!string.IsNullOrEmpty(request.PageToken))
{
startId = RedisPageHelper.GetPageCursor(userId, request.PageToken);
}
// ======================
// 情况2:没传Token,但传了PageNo → 自定义起始页
// ======================
else
{
int offset = (request.PageNo - 1) * request.PageSize;
// 先查该页最后一条数据的ID
var lastId = await _dbContext.Users
.AsNoTracking()
.OrderBy(u => u.Id)
.Skip(offset)
.Take(request.PageSize)
.Select(u => u.Id)
.LastOrDefaultAsync();
startId = lastId;
}
// ======================
// 统一高性能查询
// ======================
var query = _dbContext.Users.AsNoTracking().OrderBy(u => u.Id);
if (startId.HasValue && startId.Value > 0)
{
query = query.Where(u => u.Id > startId.Value);
}
// 多查一条判断是否有下一页
var dataList = await query.Take(request.PageSize + 1).ToListAsync();
bool hasNext = dataList.Count > request.PageSize;
if (hasNext) dataList.RemoveAt(request.PageSize);
// 生成下一页Token
string? nextToken = null;
if (hasNext && dataList.Any())
{
ulong lastDataId = dataList.Last().Id;
nextToken = RedisPageHelper.SetPageToken(userId, lastDataId);
}
文章评论