AI Programming Team Collaboration
Historical Background
The speed of AI development has accelerated remarkably. In the era when GPT-3 emerged, interaction was limited to a question-and-answer format in a dialogue box. Now, various technologies like RAG, AI Workflow, and AI Agents enable AI to perform an increasing number of tasks with more powerful functionalities. With the advent of AI IDEs such as Cursor and Trae, many have become enamored with this technology capable of revolutionizing traditional workflows, especially in the programming domain. The wave of transformation is particularly swift — initially, when faced with complex business functionalities, obscure syntactic implementations, or unfamiliar framework calls, developers no longer need to spend considerable time reviewing documentation or debugging code. Instead, they can simply describe their needs to the AI in natural language and obtain usable code snippets through its question-and-answer responses. This not only significantly lowers the programming barrier but also liberates developers from repetitive foundational coding tasks, planting the seeds for more advanced programming paradigms such as dialog-based code generation, Vibe Code, and even Spec Code.
Currently, the mainstream AI-assisted programming primarily involves AI Agents. Developers input the desired functionality into the AI IDE, where the AI automatically reads project files, reflects on the task, and writes the corresponding code, including automatically correcting any code errors to ensure successful compilation. This is the dialog-based AI code generation spurred by large language models (LLMs), marking the beginning of a new era of code generation through natural language interaction. Developers engage in multi-turn dialogues with the AI to produce code snippets and manually integrate them, with AI serving merely as an assisting tool. Subsequently, the evolved Vibe Code paradigm allows developers to drive the AI's complete coding and iterative processes with just high-level intent descriptors, shifting the human role from coder to needs guide and tester, focusing on rapid prototyping and creative validation.
However, the AI-assisted programming under the AI Agent model also faces several common issues, which have become popular topics in the IT community illustrated by the following meme:
Image courtesy of the enthusiastic netizen "Diga".
Although the above image is humorous, let’s classify the issues into two parts: large language models and AI IDEs. Below are the common problems encountered in AI-assisted programming.
Large Language Models:
-
Goal Drift: In multi-step and lengthy programming tasks (such as complex feature development and project refactoring), the AI can easily deviate from the initial target in the later stages. For instance, if the original intent is to optimize database query performance, it might inexplicably end up rewriting UI components, indicating a lack of effective target anchoring mechanisms.
-
Repetitive Errors: Lacking long-term memory for previously encountered errors, the same issues reoccur (e.g., incorrectly handling the
awaitkeyword in asynchronous functions, erroneous file path references), making it impossible to automatically encapsulate historical solutions. -
Context Explosion: To ensure the AI grasps complete project information, one must cram a substantial amount of code, requirement documents, and historical dialogue into the context window, leading to decreased model processing efficiency, response delays, and missing key information.
-
Progress Loss: Relying on the dialogue window to store task states, any reset, refresh, or interruption of the session results in the loss of previous development progress, intermediate decisions, and accumulated project understanding, creating difficulties in seamless continuation.
-
Hallucination Generation: In the absence of clear reference points, there is a risk that AI will fabricate non-existent API methods, syntax rules, or project configurations, generating seemingly reasonable yet non-functional code, thus increasing debugging costs.
AI IDE:
-
Insufficient Context Management: Most AI IDEs lack independent external memory mechanisms. They still depend on the AI model's built-in context window, making it difficult to efficiently correlate project files and historical operation records, thereby straining coherent development for complex tasks.
-
Lack of Task Tracking and Visualization: Most AI IDEs lack structured task breakdown and progress visualization functions, failing to clearly present stage divisions, completion states, and decision basis, making it difficult for developers to grasp the AI's work trajectory.
-
Weak Error Record and Reuse: The absence of an integrated error tracking system means that errors faced by the AI and their remediation solutions are not automatically archived — hindering developers' ability to trace the root of problems and preventing the AI from rapidly reusing verified solutions in the future.
-
Insufficient File Collaboration and Persistence: There is a lack of a unified storage and management mechanism for intermediate products generated by the AI (like research notes and technical documentation), resulting in file dispersion and loss, which prevents the formation of a traceable and reusable project knowledge repository.
-
Poor Human-Machine Collaboration: Developers find it challenging to directly intervene in the AI's task execution process, such as adjusting development directions through editing structured planning documents or having easy means to review the AI's decision logic, leading to inefficient human-machine collaboration.
-
Performance and Cost Imbalance: When handling large-scale projects, frequently loading the entire context may cause the IDE to lag. Moreover, repetitive processing of identical static content (like project framework definitions and tool configurations) increases token consumption and raises usage costs.
Therefore, given the current technological limitations, playing with AI programming has its restrictions, and using AI for coding often presents numerous obstructive problems, affecting both coding experience and the quality of project code.
Pain Points and Core Demands of Team Collaboration under AI Programming
Having introduced the common issues and technological constraints that can easily arise in AI programming, we now return to collective AI programming collaboration at the team level. When teams lack standardized collaboration mechanisms, AI programming can easily fall into the "individual combat" dilemma, resulting in several more headaches.
The author, who leads a project group at the company where several members have taken to using AI to write code, has observed and reflected on some issues over time, leading to the impulse to write this article. I believe these issues are also prevalent in various companies.
Code Fragmentation
Many colleagues have discovered that using AI to write code can lead to getting off work earlier; hence, everyone uses AI for coding, leading to members having widely varying styles and logic in generated code, causing difficulties in module integration and dramatically increasing maintenance costs. Simply put, when colleagues use AI-generated code, I hardly want to maintain it.
Norm Control Loss
Most of us can relate to the experience that AI-written code differs widely in style based on various prompts and functional implementations, lacking a unified standard and style. The generated code may drift from team coding standards and security protocols, posing potential quality risks.
Knowledge Silos
Individual experiences accumulated using AI cannot be shared, making it difficult to enhance the overall efficiency of the team. You use Cursor, I use Kiro; we each write our own code, making it impossible to embed knowledge and experiences within the team. Prompts, feature history, and background context cannot be shared, requiring each person to use AI locally to read context memories for generated code.
Collaboration Inefficiencies
The above scenarios can lead to situations where AI generates bloated code for simple functionalities; it’s possible for colleague A to generate a version of C while working on functionality A and for colleague B to generate a similar C while working on functionality B, resulting in a tangled web of project code intricacies. This complicates task allocation and code review processes, leading to delayed information transmission and frequent conflicts.
Besides resolving the above issues that arise during team-based programming, many companies have code quality specifications, security protocols, and unit test coverage requirements. Based on these problems and common company coding requirements, I believe that core demands for team AI programming should focus on:
- Maintaining consistent code quality
- Preventing security vulnerabilities
- Reducing redundant workloads
- Standardizing collaboration processes
- Accelerating development cycles
- Achieving a transition from "rapid prototyping" to "engineering implementation".
Many leaders find it hard to evaluate AI programming, believing it could “reduce costs and increase efficiency.” A project that typically takes a month to complete could be finished in a day using AI, and the code might even be better than what developers could write, leading to calls to reduce the workforce significantly by promoting AI programming in the company.
There will be later discussions on how much AI-assisted programming can speed things up, but it’s unlikely one can finish a month’s worth of work in just one day.
In reality, unless one is opening a blind box, the quality of the product depends on how well the AI can generate the code. Initially, the speed can indeed be very fast. However, in the later stages, AI-generated code can become difficult to maintain, and if one solely relies on AI for coding, considerable time might be spent crafting prompts — leading to ongoing disputes with the AI for even minor requirements and eventually resulting in chaos.
As I mentioned previously, there are current technological limitations in both large language models and AI IDEs, along with many collaboration issues that arise with team AI programming. If there are no solutions to address these problems, the code generated by AI could end up a disarray, potentially rendering it unreadable by humans, leaving us wondering what the AI actually generated.
Integrating AI programming into a company can indeed accelerate development speed and shorten development cycles. However, it shouldn't be absurdly assumed that “one month’s workload can be done in a day with AI.” I believe that beyond pacing up the work, there should be a greater emphasis on realizing the core demands of AI programming mentioned above.
Many companies incessantly advocate for unit tests, coding standards, and high-performance, high-quality code, setting unit test coverage and code review metrics for developers, which leads to a constant state of agitation without resolving diverse management and technical issues. Blindly imposing rigorous development standards fails to address current challenges and contributes to developer fatigue.
I articulate these points because code review, coding standards, and unit tests are not easy to implement. How many companies can repeatedly manage these requirements successfully?
Whether these can be done well actually relates to the company culture and the difficulty of implementation.
In essence, it is only when standards are sufficiently simple that they can genuinely be put into practice.
Thus, I have been considering how to resolve the pain points of team collaboration in AI programming while meeting core demands and genuinely implement technical requirements like unit testing and code reviews.
This is the focus of this article: what exactly is AI Spec and how to execute it? Following that, the article will explore this from an architect's perspective, examining how we, as architects, can integrate AI programming into team collaboration.
Specification Development
As previously noted, AI-assisted programming is gradually becoming mainstream. Most developers now use AI to write code in their daily tasks, but this also introduces many challenges, generating a plethora of unpredictable code with varying quality. To address these issues, SDD (Specification-Driven Development) has arisen, emphasizing that before engaging in AI programming, there should first be a Specification in place to constrain AI's generation of high-quality code that meets business needs and technical requirements.
Currently, there are mainly three types of SDD tools in the community: OpenSpec, Kiro, and Spec-Kit.
In order to implement Spec development, the following considerations should be made when choosing SDD tools:
-
Tool and Process Adaptation: Select AI tools like Kiro that support specification customization and multi-scenario collaboration to avoid disconnection between tool functionality and team processes;
-
Focus on Norm Implementation: Transform team rules into executable hooks and spec templates to be enforced by AI rather than remaining at the documentation level;
-
Cultivate a Collaborative Culture: Encourage team members to share experiences using AI and engage in process optimization, avoiding an "individual combat" mentality;
-
Balance Automation and Manual Input: AI should handle standardized, repetitive work (such as testing and compliance checks), allowing human focus to remain on core architecture and creative decision-making, thus achieving efficient human-machine collaboration.
In this article, I will specifically elaborate on the content involved in deploying Kiro.
During the research process, I came across several well-written articles that readers may find useful, so I won't delve into these SDD tools in detail here.
In-depth comparison of the three AI-driven development tools: Spec-Kit, Kiro, and OpenSpec - Technical Stack:
https://jishuzhan.net/article/1988226029513670657
Transforming Dev Practices with Kiro’s Spec-Driven Tools | AI Native Dev
https://ainativedev.io/transforming-dev-practices-with-kiros-spec-driven-tools
Let's briefly introduce Kiro.
Kiro is an AI IDE launched by Amazon Web Services, focusing on “Specification-Driven Development” and perfectly fitting team collaboration needs.
Friendly for domestic users, no special network configurations are needed.
Team Alignment: Core Concept Analysis of AI Programming
Before delving into team collaboration practices, it is essential to clarify the key technical concepts supporting AI programming. Regardless of product concerns or testing, it is crucial to understand concepts like LLM, MCP, and Agent. The entire team must be on the same page, ensuring that there are no knowledge barriers in communication and collaboration.
I will not reiterate the specifics of these concepts.
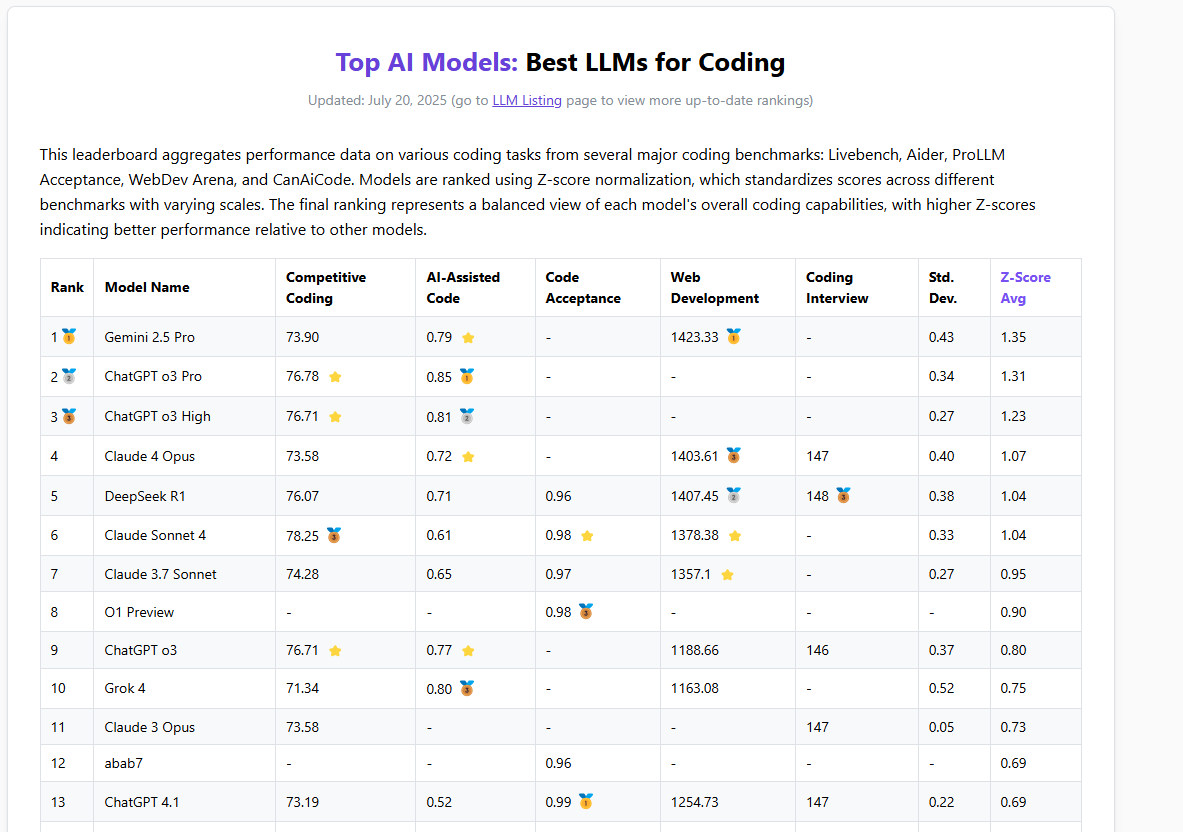
It’s essential for architects to have a clear understanding of the scoring of mainstream large language models used in programming, recognizing each model's strengths and weaknesses to discern which model is optimal for programming applications.
I have found several excellent websites featuring introductions and rankings of various models:
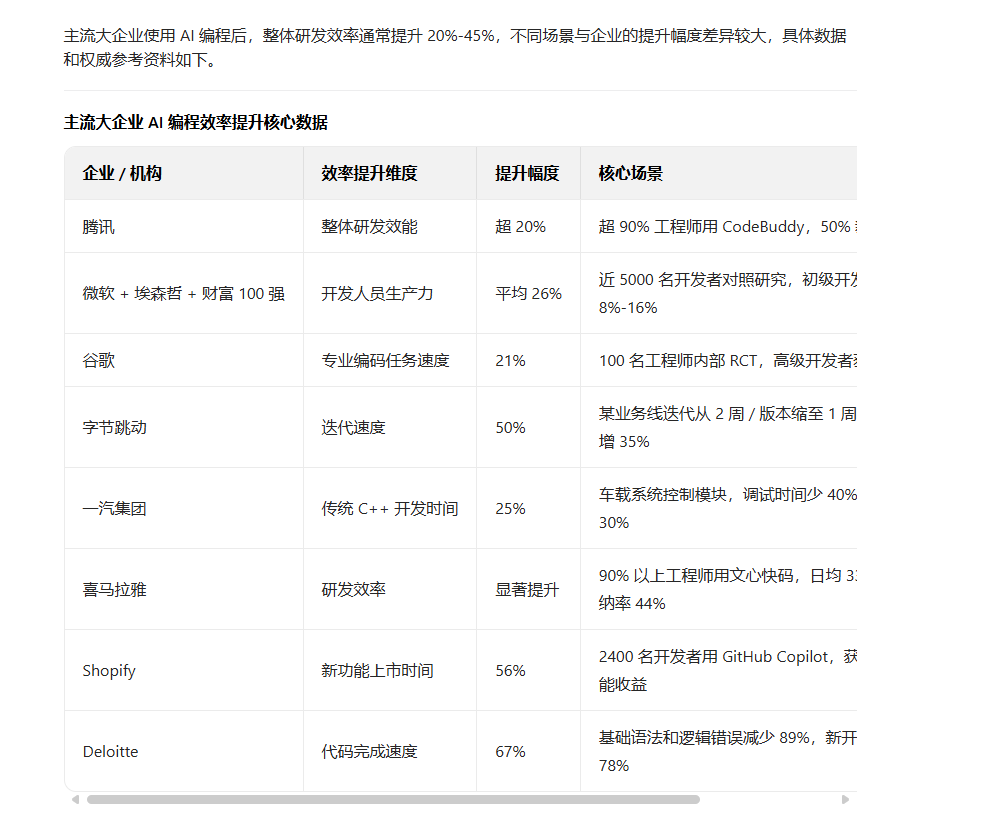
Mainstream enterprises employing AI-assisted programming report improved efficiency.
It could cause awkwardness if a leader believes AI can produce better code in a day than what you create in a month. As technical personnel, it is critical to reasonably assess the overall efficiency improvements and coding speed increments the entire team achieves through AI programming.
For example, according to a research report, the coding speed for task completion improved by approximately 21%. The report can be found at: https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
Meanwhile, information from Doubao Network suggests that the improvement in development speed may not be as exaggerated.
In summary, creating a team capable of AI-assisted programming necessitates adequate knowledge of AI among team members, understanding foundational concepts, and striving for cognitive alignment in AI programming; otherwise, various mishaps may arise, leading the team to laughter-worthy situations. Knowledge and consensus are critical, or else the team may easily fall apart.
Project Templates
The need for development frameworks should not require extensive explanation; C# developers should be familiar with the ABP framework, while Go developers should know about Gin and Beego. Utilizing frameworks significantly alleviates development burdens. Even within the context of using development frameworks, teams need to customize project templates to adapt to the company's tech stack while aligning with specific company technical requirements, such as auditing attributes, microservice communication methods, and authorization. Well-designed project templates can unify development patterns and habits.
While writing my personal open-source project, I drew from DDD, clean architecture, CQRS concepts, and integrated AI programming to form my development practices. Thus, to write this article, I organized a template project:
https://github.com/whuanle/aispec
In line with my development habits, I opted for a modular + CQRS structure, with each business domain adhering to a three-tier modular architecture. Whether for development or unit testing, this approach is relatively straightforward.
src/{domain}/
├── MoAI.{Domain}.Shared/ # Shared Layer - Definitions for DTO, Command, and Query
├── MoAI.{Domain}.Core/ # Core Layer - Handler implementation, business logic
└── MoAI.{Domain}.Api/ # API Layer - Controller/Endpoint exposureDependency flow: Api → Core → Shared, with specifics referenced here:
Coding constraints reference: https://github.com/whuanle/aispec/blob/master/.kiro/steering/cqrs-conventions.md
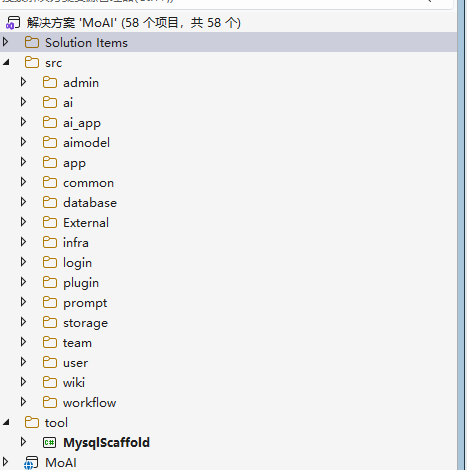
Specific design thoughts and various details will not be elaborated on. This section's purpose is to emphasize that regardless of the development framework used—whether DDD or traditional three-layer structure—teams should have a unified project template and constraints regarding development practices. AI will reference the project's existing code and steering files to write compliant code, thus preventing whimsical coding practices.
I won’t expand further on the template project; readers can find this practical demonstration template project here: https://github.com/whuanle/aispec
Preparing to Customize Team Rules and Project Index
When using AI programming, several common problems may arise:
-
Developers can easily fall into blind conversations with the AI, failing to receive the desired code, resulting in low usability and certainty of produced code.
-
Developers find it challenging to convey target solutions and code clearly and accurately to the AI IDE.
-
The need to invest considerable effort upfront to draft and accumulate project Rules and Documentation.
-
Relying on AI for everything often results in unsatisfactory proposals.
While resolving these issues is not inherently difficult, bringing them into team collaboration requires architects to contemplate broader aspects, ensuring code quality and development efficiency while avoiding repetitive issue resolution.
What is Steering?
Here, "steering" refers to a concept within Kiro, aiming to ensure that throughout the AI programming process, the AI adheres to established team patterns, libraries, and standards.
In other words, based on the project template of the team, we need to define some technology constraints unrelated to the business, such as how to specify auditing attributes, how to utilize the development framework/project template, and the naming conventions for different functional code files, among other elements, all of which can be documented within Kiro's steering. The AI will then generate code while consistently aligning with these steering guidelines; if the AI's code does not meet the steering requirements, it will progressively refine the code.
So, does establishing code standards within teams become simpler? Can we solve the problems noted before regarding AI programming and meet our core demands?
Yes, thus emphasis should be placed on project templates and steering. Before team development fulfills requirements, a steering should be customized for the entire team or even the company's research and development department.
Common Steering Document Strategies
Later sections will discuss the default steering rule templates available in Kiro, but from a team perspective, additional steering documents may be necessary:
API Standards (api-standards.md) - Define REST conventions, error response formats, authentication processes, and versioning strategies. This includes endpoint naming patterns, HTTP status code usage, and request/response examples.
Testing Methods (testing-standards.md) - Establish unit testing modalities, integration testing strategies, mocking methods, and coverage expectations. Document preferred testing libraries, assertion styles, and testing file organization.
Code Style (code-conventions.md) - Specify naming conventions, file structure, import ordering, and architectural decisions. It includes preferred code structures, component patterns, and examples of anti-patterns to avoid.
Security Guidelines (security-policies.md) - Document authentication requirements, data validation rules, input sanitization standards, and vulnerability prevention measures, including secure coding practices specific to your application.
Deployment Process (deployment-workflow.md) - Outline build procedures, environment configurations, deployment steps, and rollback strategies, including CI/CD pipeline details and environment-specific requirements.
Of course, these steering documents need not all be prepared upfront. A project template can be developed first, allowing Kiro to read the code and generate output accordingly.
Different teams in different companies may have varying requirements; the focus should be on richness in writing, gradually gathering team experience and enhancing the steering framework over time.
Core Execution: AI-Driven Collaborative Process Design
In team collaboration for AI programming, is it as simple as tossing the desired functionality into a dialogue box and letting the AI write the code?
No! That is a fundamental misunderstanding!
Let’s revisit Kiro’s introduction: 'Agentic AI development from prototype to production’.
Note that in AI programming, we are tasked with handling the entire cycle from prototype to product, rather than merely using AI to complete code and get off work early.
Hence, considerations include what roles the team encompasses, how everyone should participate in collaboration, and most importantly, how new team development processes can be designed.
Given that different companies have various team compositions, I will explain the subsequent content based on a conventional team setup (comprising Product, UI Design, Frontend, Backend Developers, and Testers).
Thanks to the article by this author, which inspired many ideas for me: https://aicodingtools.blog/zh/kiro/kiro-spec-guide
After incorporating AI programming, responsibilities for each role within the team will need to adapt. The output work should be identifiable and usable by the AI and circulate within the team.
If the product's requirement document cannot be analyzed or summarized by the AI, how logical can it be when presented to developers? If the logic is nonsensical, how will the AI be able to write code based on it?
The requirement document from Product can be organized by developers first, then serve as prompts and requirements constraints for the AI to produce code—significantly reducing the burden on developers.
Developers and testers will increasingly depend on requirement documents (or other documentation forms), since the requirements will serve as a basis for development, testing, and acceptance. At the AI programming stage, it’s essential to let the AI know that coding also involves considerations for testing and acceptance. Waiting until AI completes the code and then asking it to write unit tests to check for successful acceptance is not viable.
Additionally, the early preparation phase relies on tasks carried out by architects or leaders for architectural designs and feature implementation planning rather than vague remarks like, "Implement a short link service that reduces long links to short ones.” Technical leads need to contemplate and plan algorithms for shortening links, restoring them, how data will be stored, and ways to enhance concurrency while managing high pressure on the database.
Thus, it’s crucial to consider the following for AI programming implementation:
-
What roles does the team need?
-
What responsibilities should each role assume?
-
What stages should the entire development process consist of?
Every company is unique, and I have no explicit opinions or solutions for these questions; however, the subsequent practical sections will elaborate on the developmental stages of Kiro Specs.
I conjecture that, in the future, as AI-assisted programming becomes more prevalent, the roles and contributions within teams may undergo significant change.
Firstly, team development processes may shift from the conventional sequence of product prototype design, requirement meetings, development, and testing to an approach that leans more towards agile development methodologies aligned with AI programming.
Secondly, the scope of responsibilities for each role might evolve to ensure that information generated can be absorbed by AI, knowledge can be consolidated, and the barriers between product, design, development, and testing roles can be lessened, enhancing fluidity in information flow and team collaboration.
三是可能会出现以 AI 编程为中心的产品研发一体化平台,无论是产品、设计师、开发、测试,都可以围绕这个平台进行符合自己角色的参与,例如产品编写需求文档和验收文档时,可以借助 AI 平台检测需求是否合理、调整设计、细化需求,转化为开发人员便于阅读的文档。产品、设计师通过需求文档借助 AI 平台快速实现产品原型设计。开发人员则可以将需求导入 AI,创建开发任务,逐步与 AI 协作编写代码,还可以借助 AI 快速生成单元测试、集成测试等,最后根据验收文档验证检测最终输出。
而关于团队的研发流程,则会在 工作流程 一节详细讲解。
总结
作为文章的第二部分,主要是思考怎么建设使用 AI 辅助编程的团队,以及进行团队协作。
第三部分将会讲解实战,从原型到产品的整个环节,每个步骤应该做什么。
实战
作为文章的第三部分内容,将会以短链接服务为案例,去讲解如何落地实战团队协作和 AI 编程,去设计一个以 AI 辅助开发为核心的项目研发流程。
思考整体架构
AI 时代,还需要我去设计项目?
是的,开发人员要自行对技术方案进行调研、上手尝试,然后让 AI 根据你的方案和设计做出来,不要都让 AI 帮你做解决方案。
只需要一个 idea,AI 就可以写代码,可是 AI 写出来的东西可能跟专业人员需要的东西相去甚远,并且还有大量细节满足不了需求,开发人员可能会陷入跟 AI 的对骂中,不断调整提示词,不断等待 AI 生成,最终生成了 90% 的内容,剩下的 10%,开发人员只能对着键盘一点点敲完。
虽然是 AI 编程,但是编程的重点是人的想法和需求,而不是 AI 的天马行空,虽然 AI 实现的项目可能有很多很好的创意和想法,质量可能很好,但是对于专业领域和公司业务项目来说,需求的中心是公司对应的业务,而不是一个 idea。
而且 AI 有上下文限制,有幻觉等,你只需要一个简单的一个登录功能,可能 AI 把单点登录、OAuth2 等一堆东西给你加上去了(目标偏移)。
所以即使在 AI 时代,我们也要构思项目设计和功能实现的算法和逻辑,让 AI 在这个边界内实现代码和测试。
当然,我们可以利用 AI 去帮助我们验证想法和构思设计,然后将这些内容生成为架构设计和技术方案。
短链接服务的架构
由于本文的重点不是怎么实现一个短链接服务,所以笔者这里只简单讲解这个服务的一些算法和实现思路,以便后续使用 AI 写出符合需求的代码。
核心问题1:短链接生成和还原
核心问题2:短链接存储和查找
笔者的设计是,短链接跟长链接无直接映射关系,也就是不能通过算法转换直接将长链接生成短链接。
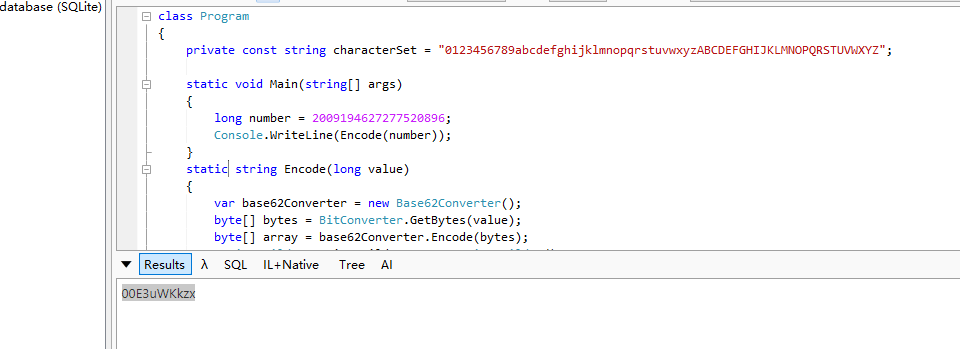
对于每个长链接,创建记录存到数据库时会使用 int64 雪花做主键,存到数据库。
例如新增一个长链接 https://whuanle.cn,当前雪花id 是 2009194627277520896,经过检查数据库没有重复数据后存储到数据库。
接着,将雪花 id 使用 base62 生成短链接编码。之所以使用 base62 做缩短编码,是因为[0-9]、[a-z]、[A-Z] 刚刚好是 62 个字符,能够在不使用特殊符号的情况下,使用数字和大小写字母表达值,也就是相当于 62 进制。将 2009194627277520896 使用 base62 编码是得出字符串是 00E3uWKkzx,而存数据只需要一个 int64 就行。
满足能够将长链接生成短链接,存储空间小,不容易被人碰撞规则的需求。
有了短链接生成和还原算法后,我们继续聊一下数据查找。
用户访问 /00E3uWKkzx 时,还原得到 2009194627277520896,然后通过这个 id 从数据库查找数据得到 https://whuanle.cn,然后让用户跳转到这个地址即可。
每次都要查数据库,数据库压力大,而且万一被人攻击,机器人随机拼接的字符串,也要到数据库检查数据在不在,数据库迟早被打崩。
所以第一层是使用 redis 的布隆过滤器,先判断数据是否存在。

第二层,数据分片,将数据存储到 redis,避免频繁从数据库查找。还可以做本地离线缓存,避免高频度从 redis 查找数据。
也就是最终是三层缓存。
其它就不多说了,前面提到的算法处理逻辑,将会作为后续 AI 编写功能的依据。
模板项目
首选是安装笔者提供的项目模板。
dotnet new install Maomi.AiSpec.Templates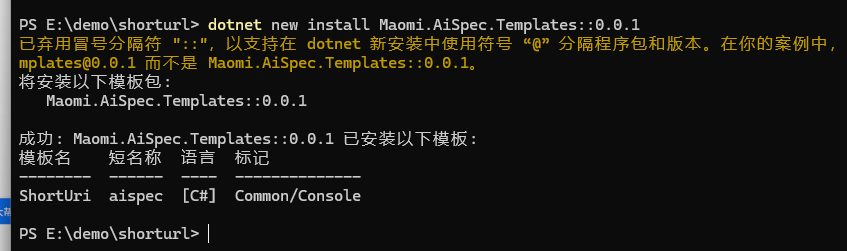
执行命令从模板创建新的项目,将 MyShortUri 替换为你需要的项目名称即可。
dotnet new aispec -n MyShortUri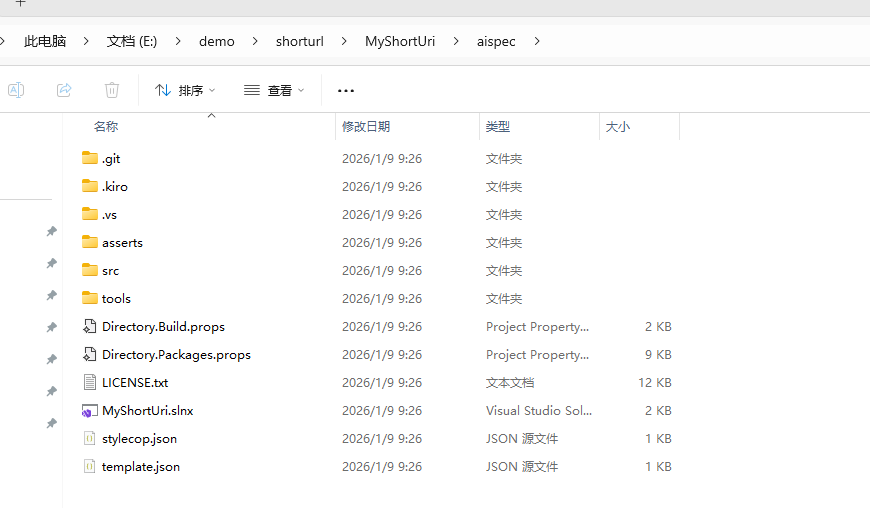
后端开发原则和规范
使用 Kiro 打开 MyShortUri 项目,在 AGENT STEERING 菜单可以看到已经模板自带四个 steering 文件。

Kiro 通过 .kiro/steering/ 目录中的 markdown 文件设置项目约束规定,Kiro 只规定了 product.md、tech.md、structure.md 三个文件,这些基础文件默认包含在每次交互中,形成 Kiro 项目理解的基线。
cqrs-conventions.md 则是笔者的模板项目的开发规则,约定 AI 生成的代码文件如何存放以及代码格式约束,AI 会生成符合项目要求的代码。
读者也可以创建一些其它文件,例如 rest-api.md 要求生成的 api 接口需要符合 restapi 格式,将公司研发规范等写入到 .kiro/steering/ 目录。
后端代码规范约束
cqrs-conventions.md 是笔者自定义的 steering 文件,用来约束 AI 生成的代码必须分为 Command/Query、Api、Handler 三层的 CQRS 结构。
定义了很多约束规范,这里就不讲解了,自己研究一下。
我要做什么样的产品
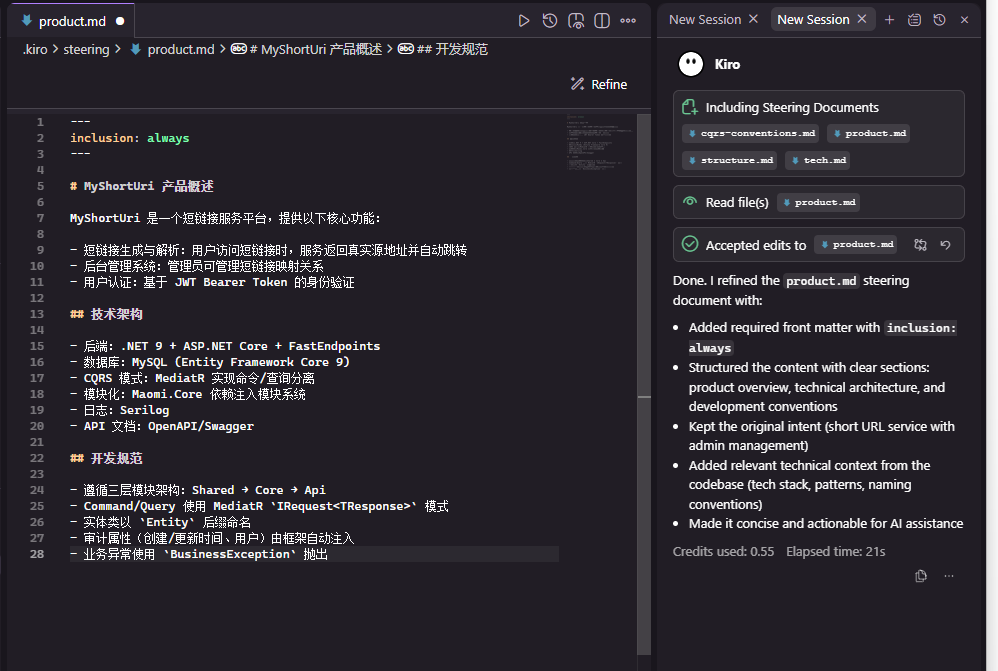
拉取项目模板后,第一步是修改 product.md,告诉 AI 这是一个短链接项目。
产品概述 (
product.md) - 定义产品的目的、目标用户、关键功能和业务目标。
一般来说,产品概述 (product.md) 是产品经理的工作任务,开发只需要将产品经理写的文档拷贝到代码项目即可,不过既然现在没有产品经理,我们可以一句话描述核心需求,让 Kiro 帮助我们生成具体的产品说明,等 AI 生成后,根据实际情况,调整好 product.md 文件。
生成效果:
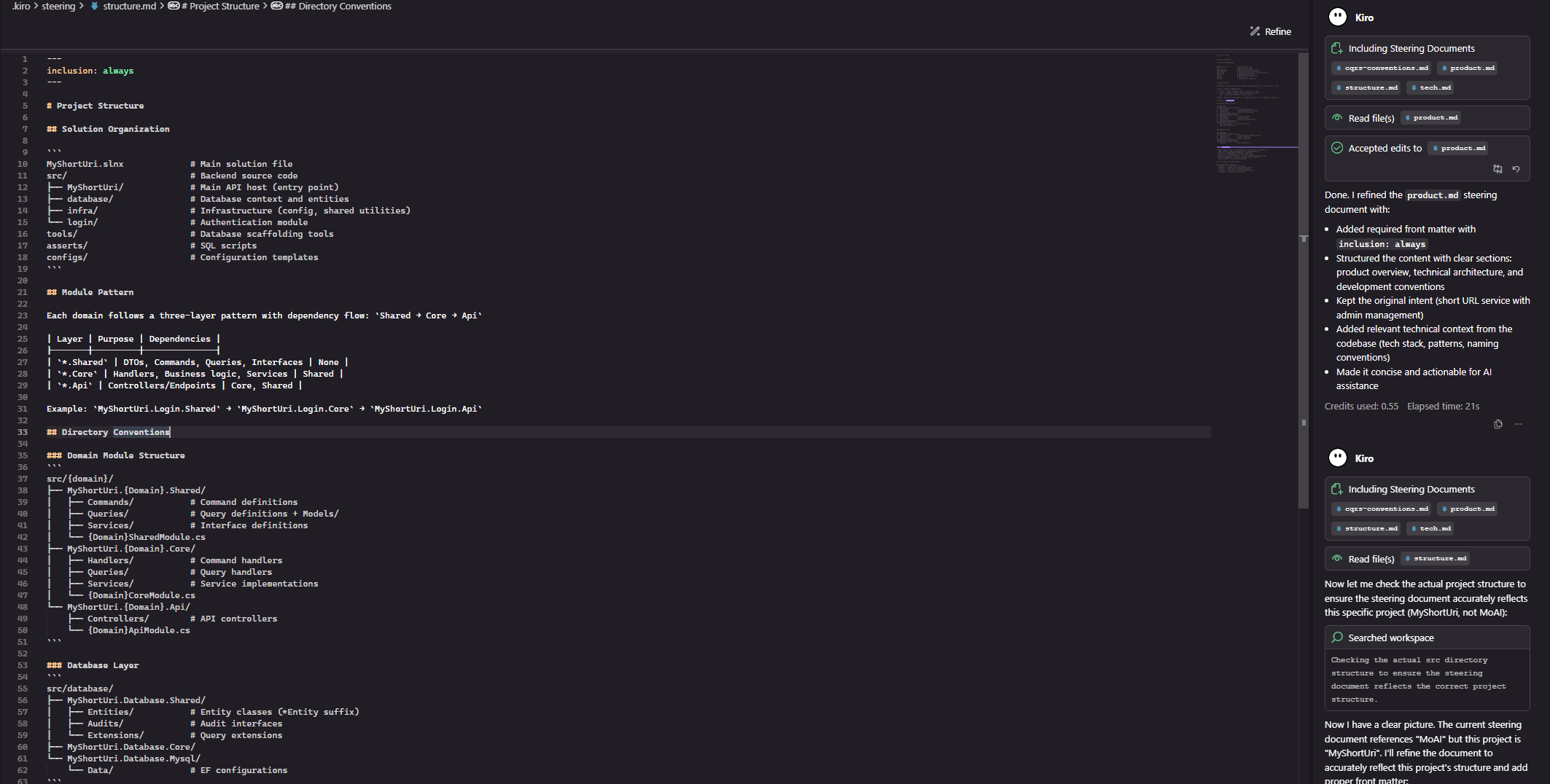
项目结构
项目结构 (structure.md) - 概述文件组织、命名约定、导入模式和架构决策,这确保生成的代码无缝融入现有的代码结构里面,这样 AI 不会乱创建文件以及随便找个地方塞代码。
structure.md 要常常随着项目的进展而更新,不要一直不变,每次新增模块后,都要重新生成 structure.md 。
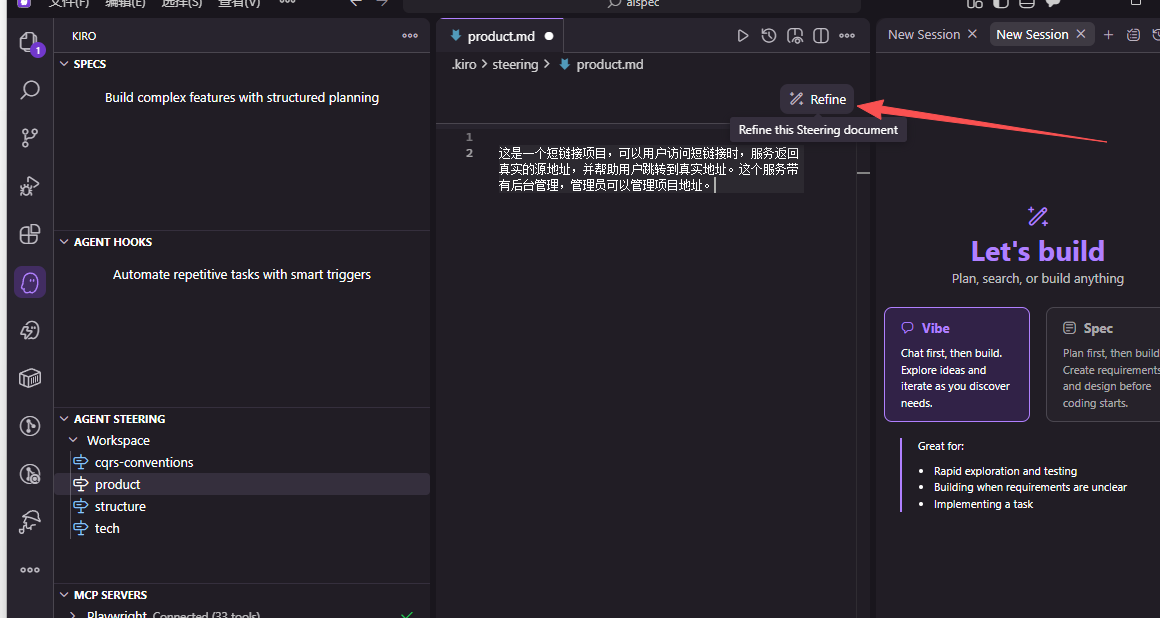
现在我们点击 Kiro 的 Refine ,重新生成 structure.md 。
技术约定
技术栈 (tech.md) - 记录这个项目选择的框架、库、开发工具和技术约束,当 Kiro 建议实现方案时,它会优先选择已建立的技术栈而非替代方案。
突然想起来一个事情,某同事写 Go 语言程序需要解决一个打印功能,结果用 AI 写的代码引入了 python,后面被我发现了,我要求用 Go 重写,然后某同事又用 AI 劈里啪啦写了一天,总算用 Go 写出来了。
所以 tech.md 可以避免这种情况,不然 AI 为了实现一个功能,到处查资料,然后引入一堆依赖,用一种意想不到的方式去实现功能。
现在我们点击 Kiro 的 Refine ,重新生成 tech.md ,例如这个项目使用的技术栈如下:
| Category | Technology |
|----------|------------|
| Framework | ASP.NET Core 9 |
| Language | C# 12 (nullable reference types enabled) |
| ORM | Entity Framework Core 9 (MySQL) |
| CQRS | MediatR |
| Validation | FluentValidation |
| Authentication | JWT Bearer tokens |
| Logging | Serilog |
| API Docs | OpenAPI/Swagger with Scalar UI |
| Caching | Redis (StackExchange.Redis) |
| Module System | Maomi.Core |
| Code Analysis | StyleCop.Analyzers |作者还可以加上接口设计约定等文件,这里不再赘述。
数据库设计
现在出现了一个使用 AI 做数据库设计方案的方向:Text2SQL。
Text2SQL 指将自然语言转换为 SQL 的技术,当一个项目从零开始时,我们可以借助 AI 构思、设计项目架构,最后总结输出 SQL,这一步其实比较简单。
但是后续项目迭代后,需要 AI 去了解整个数据库表结构,需要 AI 根据业务情况设计新的索引、字段约束等,这就要求 AI 需要挖掘数据价值,应对复杂的分析任务,才能给出合理的数据库变更建议。
可以借助专业的 AI DB 客户端去做,例如 Chat2DB、也可以在 Kiro 装上 MCP 工具读取数据库,由于不是本文重点,这里只讲解思路,就不再详细讲述。
数据库创建表,以便后续实战让 AI 写代码。
CREATE TABLE <code>short_url</code> (
<code>id</code> bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '唯一ID(对应短链接编码)',
<code>long_url</code> varchar(2048) NOT NULL COMMENT '原始长链接',
<code>hash</code> varbinary(32) NOT NULL COMMENT '网址哈希值,方便对比',
<code>create_user_id</code> int(11) NOT NULL DEFAULT 0 COMMENT '创建人',
<code>create_time</code> datetime NOT NULL DEFAULT current_timestamp() COMMENT '创建时间',
<code>update_user_id</code> int(11) NOT NULL DEFAULT 0 COMMENT '更新人',
<code>update_time</code> datetime NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp() COMMENT '更新时间',
<code>is_deleted</code> bigint(20) NOT NULL DEFAULT 0 COMMENT '软删除',
PRIMARY KEY (<code>id</code>),
KEY <code>short_url_hash_index</code> (<code>hash</code>)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='短链接'
CREATE TABLE <code>user</code> (
<code>id</code> int(11) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
<code>user_name</code> varchar(50) NOT NULL COMMENT '用户名',
<code>email</code> longtext NOT NULL COMMENT '邮箱',
<code>password</code> varchar(255) NOT NULL COMMENT '密码',
<code>nick_name</code> varchar(50) NOT NULL COMMENT '昵称',
<code>password_salt</code> varchar(255) NOT NULL COMMENT '计算密码值的salt',
<code>is_deleted</code> bigint(20) NOT NULL COMMENT '软删除',
<code>create_user_id</code> int(11) NOT NULL COMMENT '创建人',
<code>create_time</code> datetime NOT NULL DEFAULT utc_timestamp() COMMENT '创建时间',
<code>update_user_id</code> int(11) NOT NULL COMMENT '最后修改人',
<code>update_time</code> datetime NOT NULL DEFAULT utc_timestamp() COMMENT '最后更新时间',
PRIMARY KEY (<code>id</code>),
UNIQUE KEY <code>users_user_name_is_deleted_uindex</code> (<code>user_name</code>,<code>is_deleted</code>)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COMMENT='用户'
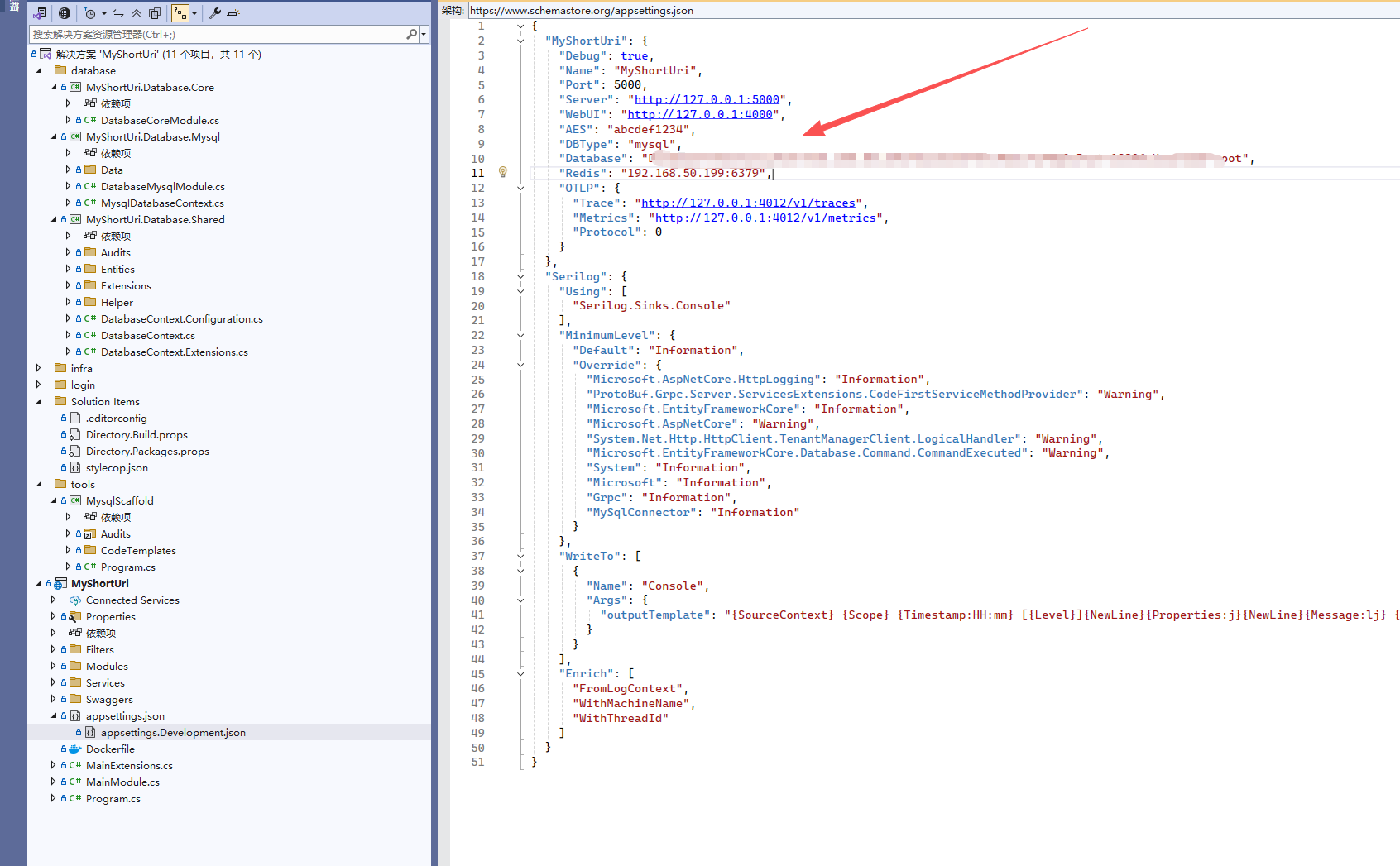
修改数据库链接,启动 MysqlScaffold 还原数据库生成代码,将 Database ,目录的文件放到对应位置接口。
您看,有个项目模板多重要,很多时候省下大量的时间,例如笔者这个模板,先设计数据库,然后定制数据库生成代码的步骤,使得生成的实体结构和 数据库上下文类能够符合业务需求,大大提高开发效率。
UI 原型设计
UI 原型设计就是 UI 设计师根据产品原型设计页面的过程,随着专业的原型设计工具支持 AI 后,产品经理跟 UI 设计师更好地协作,有时候一句话就可以生成一个不错的界面。产品经理可以借助这些 AI 工具快速实现原型页面。
由于墨刀的 AI 需要付费使用,太贵了,本来想演示 AI 根据设计稿生成页面代码的,最后放弃了,用这钱买了几盒凤爪。
本节意思读者理解就行,就是说目前市面上有很多 AI 生成设计稿的产品,产品可以不用化那么多时间画原型了,可以专心思考产品设计和流程逻辑,最大程度输出文档,把画原型这些事情留给 AI,然后还可以进一步转换为 UI,设计师也可以借助 AI 快速实现初版界面。
后端开发实战
基于项目模板和 steering,其实一句话需求,就可以让 Kiro 给我们编写一个模块的后端代码。
但是 Kiro 提出了 Specs,让团队协作和开发人员早点下班的神器。
Specs 弥合了概念产品需求和技术实施细节之间的差距,确保了一致性并减少了开发迭代。Specs 提供了一种系统化的方法,将需求和想法转化为详细的实施计划,生成验收标准、技术实现和代码生成及测试验收计划。
接下来,我们将会使用 Kiro Specs 生成某个功能的工作流程,最后根据方案生成代码并通过测试验收代码。
实现创建短链接的接口
要做短链接服务,第一步是实现一个长链接转短链接的功能,Kiro Specs 要求编码之前需要按照三阶段工作流程进行:需求 → 设计 → 实施。
在 Kiro 面板中,点击 Specs 下的 + 按钮,或者从聊天面板中选择 Spec,在对话框内输入要做的功能。
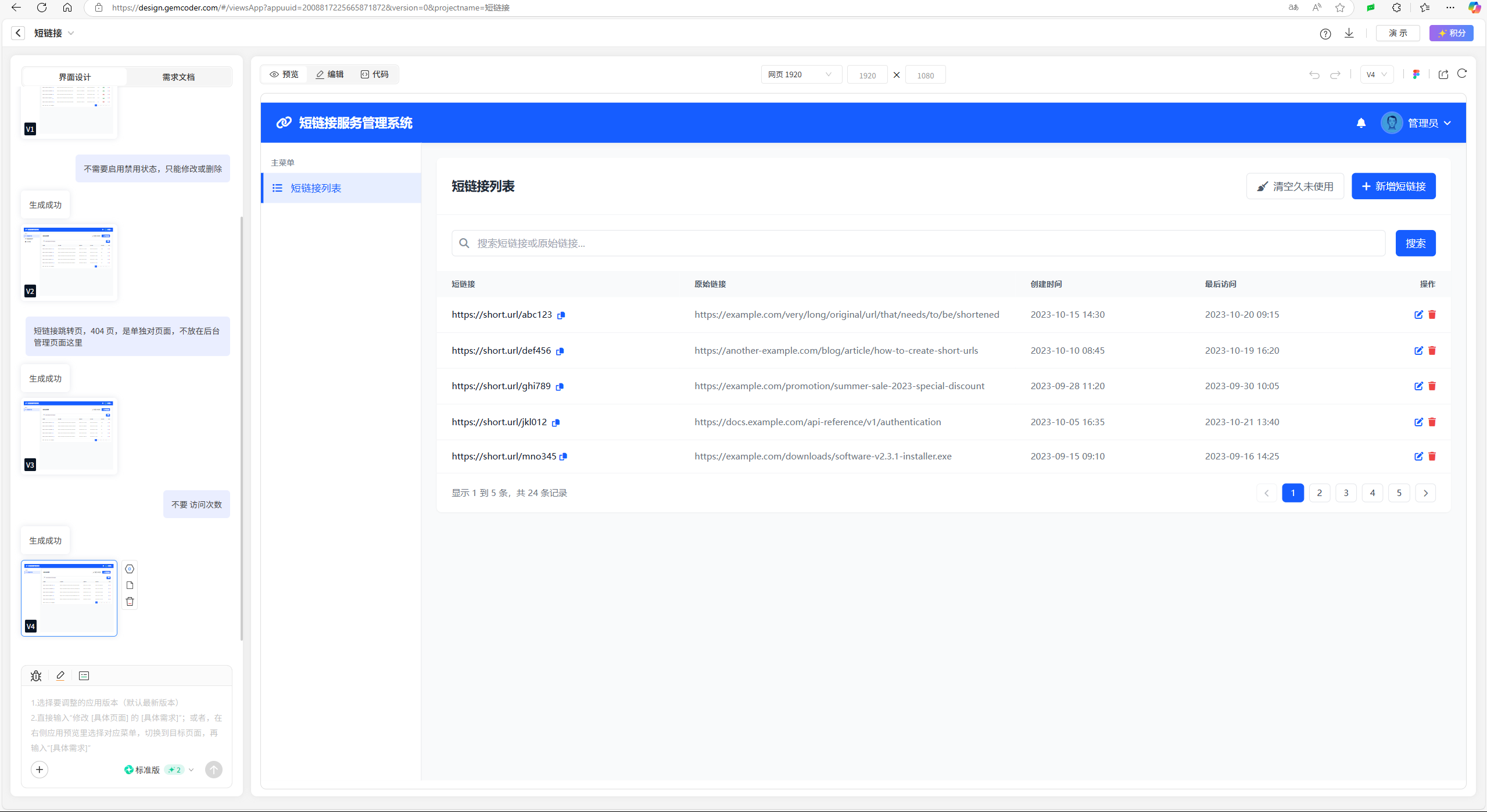
Create Spec: 实现创建短链接的接口,创建的数据存储到 ShortUrlEntity,使用雪花id赋值id,将长地址使用 SHA-256 生成 32 字节存储到 hash 字段。插入数据时要判断数据库是否存在对应的数据。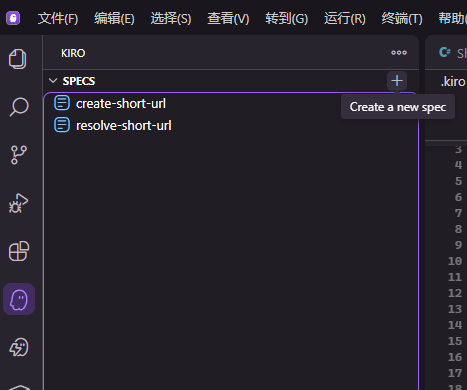
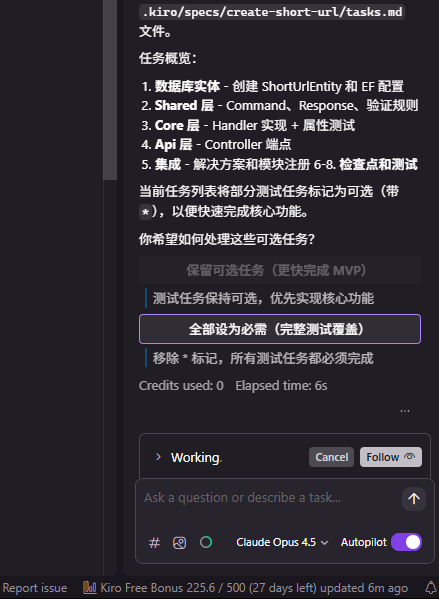
按照引导操作后,最后一步会显示 “保留可选任务(更快完成 MVP)”、“全部设为必需(完整测试覆盖)”。
如果选择了 “全部设为必需(完整测试覆盖)”,AI 在任务列表加上基于属性的测试要求和执行步骤,Kiro 从提出的需求中提取 属性 并生成测试用例,以便确保 AI 生成的代码符合开发者的意图。
Kiro 文档里面解释
属性:对于任何一组具有特定前提条件的输入,某些预期行为是成立的。Kiro 从格式化的需求中提取属性 (例如,“THE System SHALL 允许经过认证的用户查看活动车辆列表”),确定哪些属性可以进行逻辑测试,然后在你选择运行它们时生成数百或数千个随机测试用例。
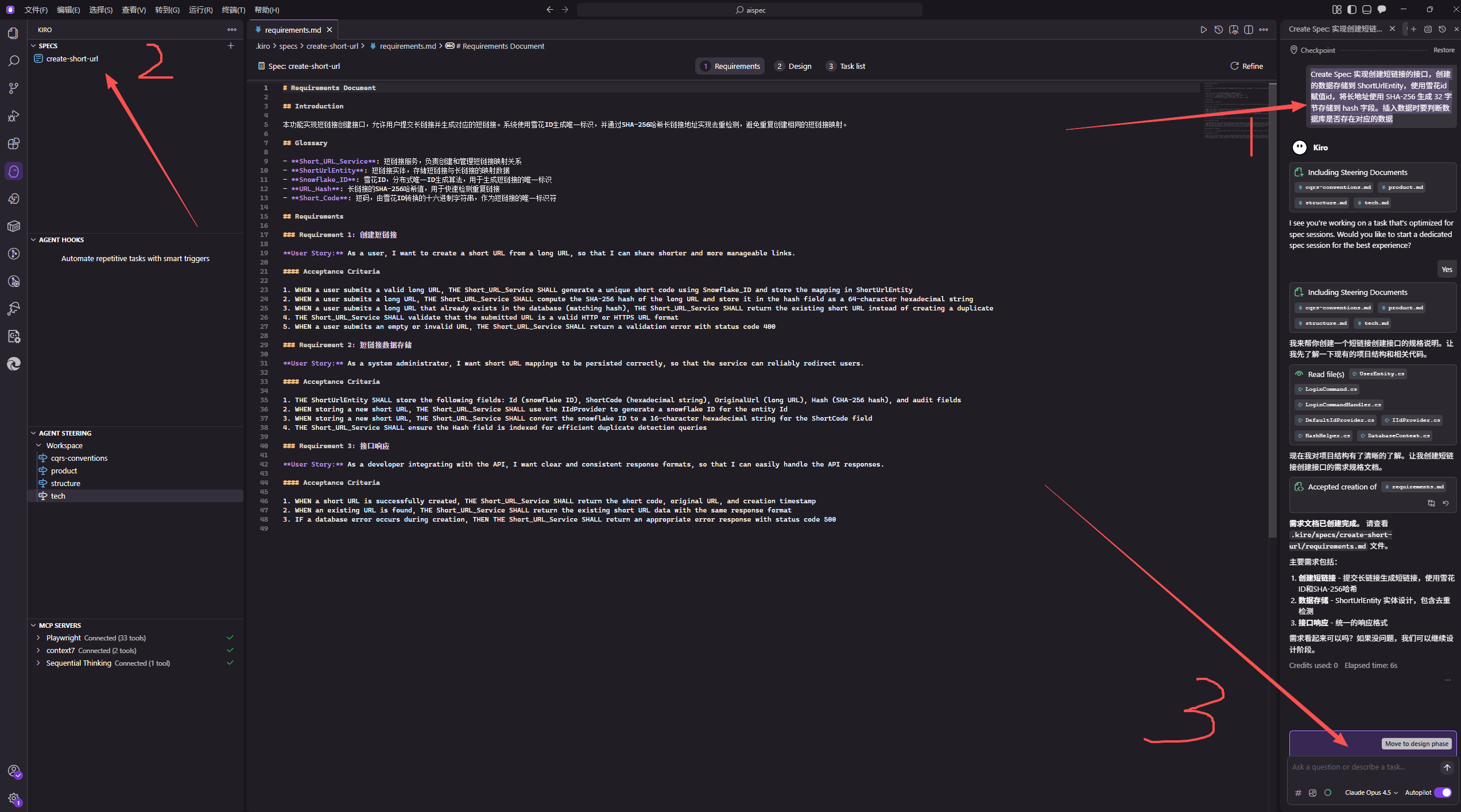
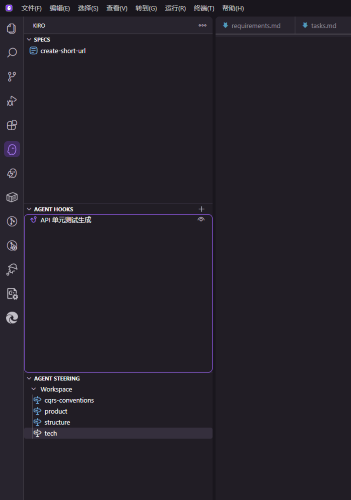
结果一顿操作后,需求已经下发到 .kiro/specs/create-short-url,Kiro 会生成三个关键文件,这三个文件构成一个 spec。
- requirements.md: Use structured EARS notation to capture user stories and acceptance criteria
- design.md: Document technical architecture, sequence diagrams, and implementation considerations
- tasks.md: Provide a detailed implementation plan with discrete, traceable tasks
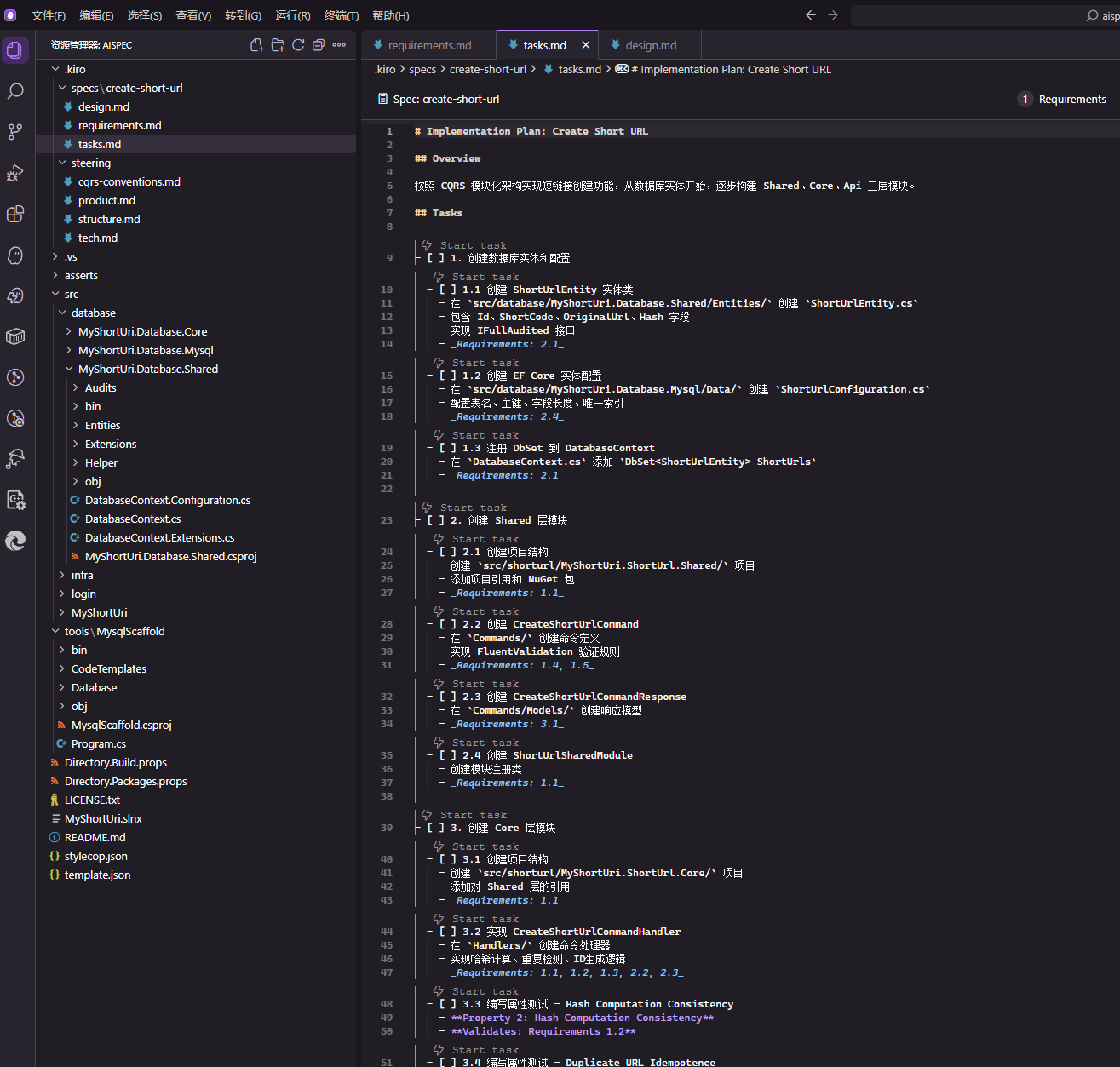
We can first edit requirements.md and design.md to ensure that the specific business requirements and test descriptions generated by AI, as well as the tech stack and implementation ideas, meet our needs. Finally, we open the tasks.md file and click the Start task button next to the task to begin implementation.

Since the algorithm used to create short links deviates significantly from my initial plan, we can regenerate the code here. However, it is advisable to write requirements.md and design.md thoroughly; do not adjust code logic in the dialogue box. Only well-established documentation is the most important.
Workflow
Using the requirement of "implementing the creation of a short link interface," we have familiarized ourselves with Kiro specs. Everyone should have a general idea of how to navigate, but returning to team collaboration, we need to consider how the development team should create specs.
In this section, we will discuss some concepts of Kiro specs to address the questions mentioned in [Core Execution: AI-Driven Collaboration Process Design](#核心执行:AI 驱动的协作流程设计), specifically how to specify a new team development process.
Requirement Phase
Kiro specs suggests using structured EARS notation to define user stories and acceptance criteria in the requirement phase, which is the content that should be written in requirements.md. The requirements.md file is formatted as user stories, containing acceptance criteria from the EARS notation.
The core tasks are as follows:
- Define user stories
- Write acceptance criteria
- Use EARS symbols for requirement specification
Compared to traditional requirement writing methods, EARS notation has significant advantages, especially when using AI programming.
| Aspect | Traditional Requirements | EARS Symbols |
|---|---|---|
| Clarity | Often vague or lengthy | Concise and clear |
| Standardization | Significant differences among teams | Unified syntax for all requirements |
| Ease of Understanding | Difficult for non-technical stakeholders | Easily understandable by all stakeholders |
| Traceability | Hard to maintain | Enhanced traceability through structured syntax |
Reflecting on our company, product managers use Feishu documents to write product documentation, leading to chaotic logic and making it very tiresome to read. Issues often arise during the development process, requiring repeated adjustments, and there are various problems during the testing and acceptance phases, resulting in a multitude of bugs after deployment. The development process and the released software are riddled with various issues. Developers blame the product managers for poorly written documentation, product managers blame developers for not understanding the requirements, and testers criticize developers for messy code.
Meanwhile, the leaders are busy customizing various "standards" requiring product managers to write product documents according to specific formatting guidelines, attempting to resolve the internal issues of the development team by prescribing a series of so-called norms.
After a deep understanding of EARS notation, it becomes evident that this method is truly suitable for team implementation, addressing common issues from product management to coding and post-testing, while also facilitating AI's understanding of requirements. AI can easily generate corresponding coding requirements and test cases based on EARS notation, ensuring that the code logic aligns with the requirements and generating corresponding acceptance documentation as the final basis for code acceptance.
The requirements.md document is divided into several sections, with the Requirements section written using EARS notation. Each requirement follows the pattern below:
When [condition/event] occurs
The system should [expected behavior] 
Design Phase
The design.md file is where technical architecture, sequence diagrams, and implementation considerations are documented. It provides a comprehensive understanding of how the system works, including components and their interactions. Kiro’s specification offers a structured approach to design documentation, making it easier to understand and collaborate on complex systems.
During the design phase, we can refer to the previously AI-generated design.md, which includes the content shown in the image below.

Implementation Phase
The tasks.md file provides a detailed implementation plan that includes discrete, traceable tasks and subtasks. Each task has a clear definition, including a description, expected outcome, and any necessary resources or dependencies. Each step can be clicked, and tasks will be updated in real-time in task.md after AI executes the tasks.
The AI-generated task.md is structured in three main steps: breaking down tasks, defining task output results, and setting task dependencies, which may also include acceptance implementation instructions at the end.
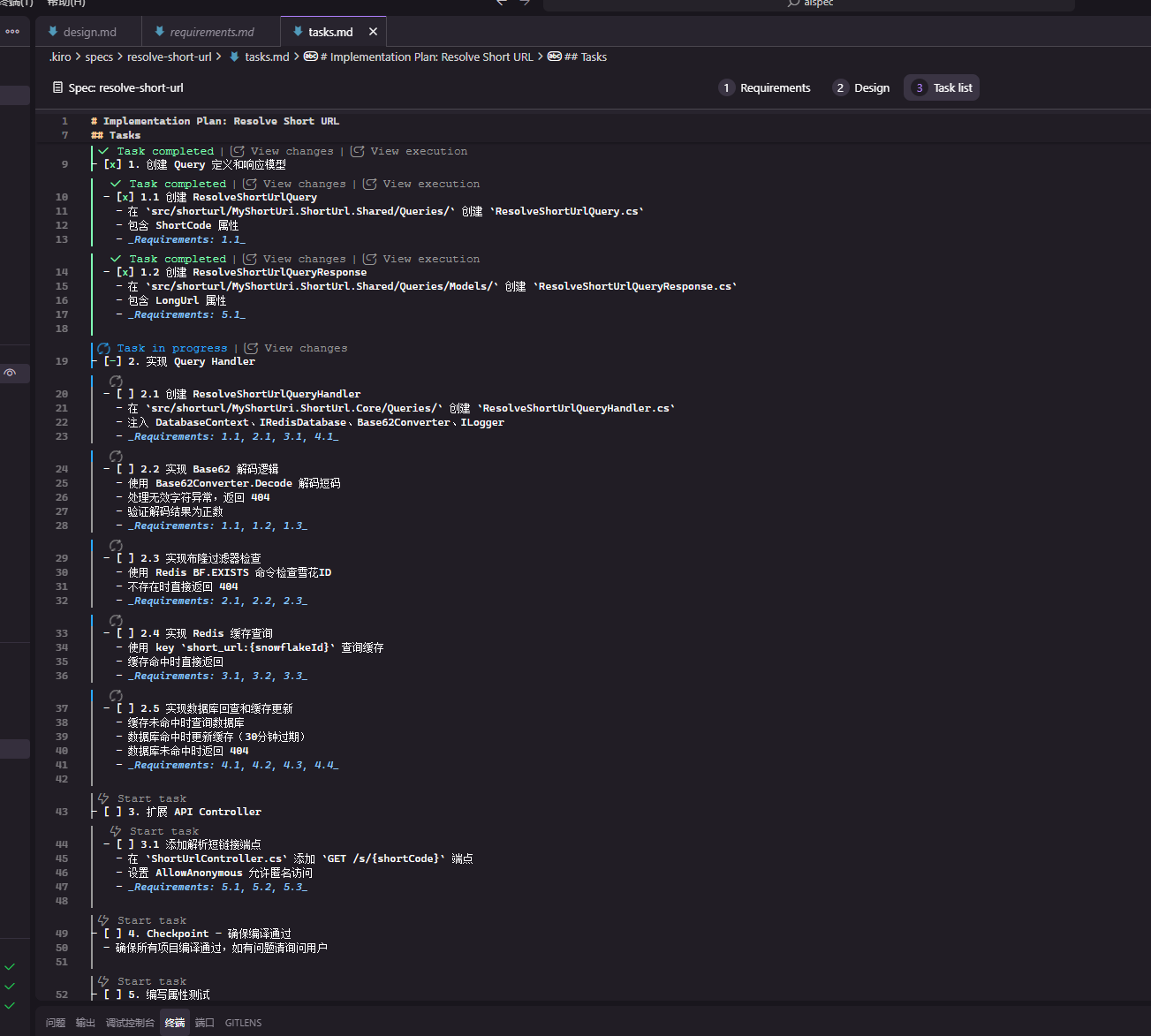
Execution Phase
This phase involves manually clicking through the various tasks in tasks.md. We should consistently track task progress and update the requirements across the three documents to improve content and ensure better AI output.
Using Hooks to Automatically Build Unit Tests
When files that match specific global patterns are created, saved, or deleted in the workspace, file hooks are triggered. These hooks require an array of patterns to specify which files to monitor.
In this section, I will use unit tests to demonstrate how to use Kiro's hooks.
Unit tests are a crucial part of a project. Since I am using a clean architecture for this template project, implementing tests is relatively simple.
There are three main areas to consider:
- For framework, tool, or algorithm code unrelated to business, a separate unit test designed for validation is sufficient.
- For model classes, it is necessary to verify parameter constraints during API requests, such as recognizing field length limits and other rules.
- For APIs and Handlers, integration tests can be written together, directly simulating requests using TestWebHost.
Now, we will write corresponding prompts to have Kiro generate the hooks.
Write unit tests for the API using EFCore in-memory databases for simulation and mock Redis for business-related framework, tools, and algorithm code, designing separate tests for validation. For model classes, verify parameter constraints during API requests, recognizing field length limits and other rules. For API and Handler, write integration tests and simulate requests directly with TestWebHost.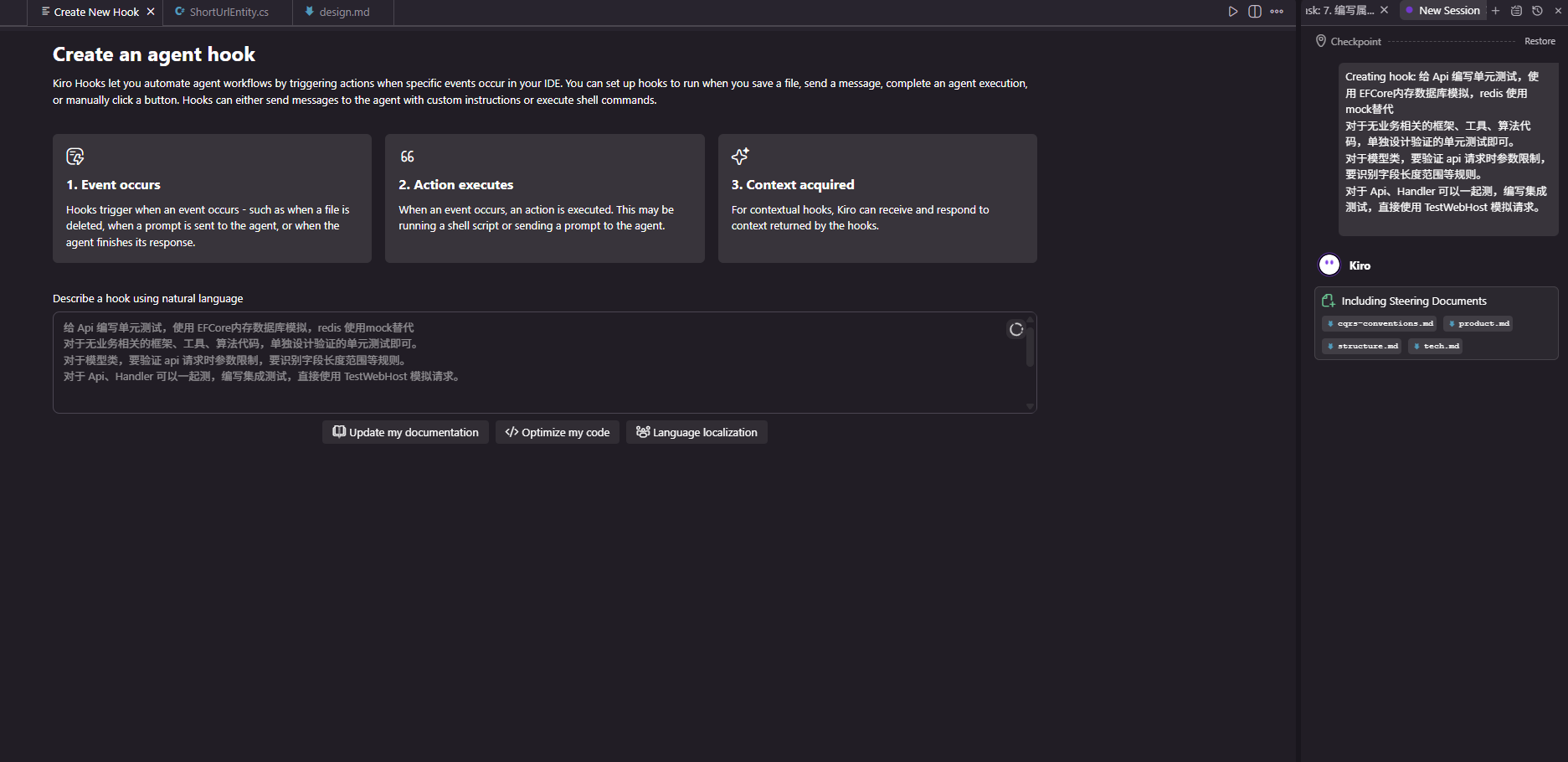
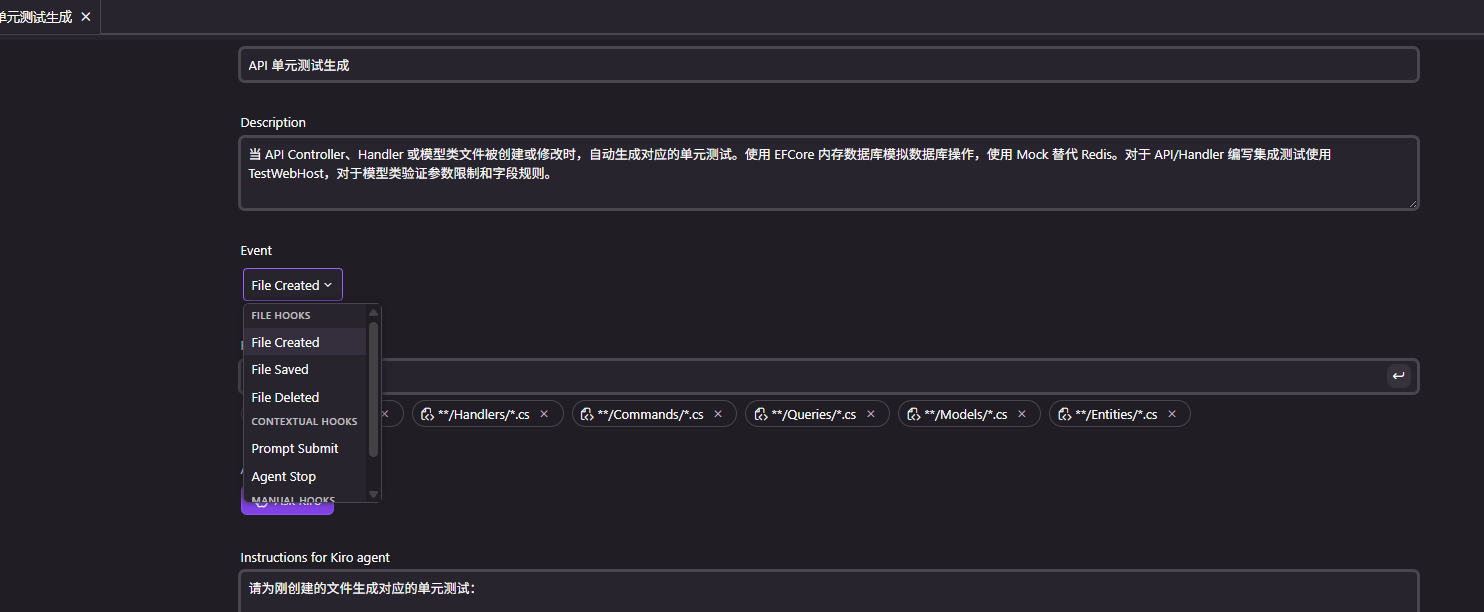
Now, we will add a new function using specs:
Create Spec: When a user accesses a short link, first restore the short link to the snowflake ID using base62, filter through the Redis Bloom filter. If not found, return a 404. Then look up from the key <code>short_url:{snowflake_id}</code>; if not found, check the database and reinsert into Redis (timeout of 30 minutes).After the creation is complete, execute the Task list.
You can wait for the hook to be automatically triggered, or inform AI in the dialogue interface to manually execute api-unit-test-gen.kiro.hook.
The final generated unit test is as follows:


Conclusion
I hope this article helps you build an AI-assisted programming team within your company.

文章评论