I found an earlier article about using Redis with ASP.NET Core, which is quite simple for beginners: https://www.cnblogs.com/whuanle/p/11360468.html
Redis Cluster Setup
What is Redis
Redis (REmote DIctionary Server) is a NoSQL data storage program that uses memory to store data structures and can function as a database, cache, or message broker.
Redis maps data using key-value pairs, and supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, and geospatial indexes.
Cluster
The official documentation on Redis Cluster can be found here: https://redis.io/topics/cluster-tutorial
When studying this, it's advisable not to rely solely on Baidu; instead, take the time to thoroughly read through the official documentation and learn bit by bit.
Redis supports three cluster modes:
- Master-Slave Mode
- Sentinel Mode
- Cluster Mode
This chapter covers setting up, testing, and operating Redis Cluster.
In Master-Slave Mode, there is one Primary and multiple Secondaries, along with replica nodes.
In Sentinel Mode, it doesn't apply.
Cluster Mode primarily aims to enhance concurrency and resolve performance bottlenecks.
Redis Cluster Overview
Redis Cluster ensures a certain level of availability for the Redis service. When some instances in the cluster fail, the remaining instances can continue to operate normally. However, if a major failure occurs, the entire Redis Cluster may stop functioning.
Each node in a Redis Cluster requires two TCP ports: one for the standard client services, usually 6379, and another for the cluster bus, which is the standard port plus 10000. For example, 163479.
Redis Cluster does not support NATted environments, meaning it does not support Docker port remapping. To use Redis Cluster on Docker, the Docker host mode must be used by adding the --net=host parameter when starting Redis.
In Redis Cluster, the functioning nodes are the master nodes (redis-master) while the slave nodes (redis-slave) back up the data of the master nodes. When a master node fails, the slave node can take over its functions.
Redis Cluster Nodes
Redis utilizes multiple instances to provide functionality, specifically sharding. Each Redis instance can act as a master node. For example, three nodes A, B, and C together form a complete Redis system. Redis Cluster automatically shards the data, distributing portions of data across each node. All three nodes can serve requests.
For instance, if there are 100 records, the first 40 could be on A, and the remaining on B and C.
There is no primary; each master node can provide services, thereby reducing server load and evenly distributing traffic among multiple nodes. If node C needs to be removed, its data can be split and pushed to nodes A and B. This is data replication.
However, if node C fails, the entire cluster will crash since the data on A, B, and C is different. This is a drawback of Redis Cluster.
For more information, please refer to the official documentation: https://redis.io/topics/cluster-tutorial.
In this document, slave nodes will be denoted with the & symbol, such as &C representing the slave of C.
Redis Cluster Modes
In Redis Cluster, each master node has multiple slave nodes, which maintain consistent data with their corresponding master nodes.
As mentioned earlier, if any master node fails, it can lead to a failure of the entire cluster. Thus, each master node should have a corresponding slave node; if C fails, &C (which has matching data) will take over C’s functions. However, if both C and &C fail, the entire system will also fail.
Redis Cluster operation relies on the redis.conf configuration file.
Next, we will manually set up the cluster step by step; this process may take some time. If you need to set up the cluster quickly, consider looking for scripts on Baidu.
To be realistic, the author uses two servers to set up a service comprising three master nodes and three slave nodes, forming a total of six nodes in the cluster.
Inconsistency Issues
When a client writes data to node C, C will write the data to &C to ensure consistency (synchronously). However, this synchronization process is asynchronous, as the user interacts with C, and the interaction returns once completed. The synchronization from C to &C is asynchronous, meaning the user cannot wait for the entire process to finish.
If the client writes data to C and C fails before it has synchronized the data to &C, that data will be lost. Therefore, this slave node cannot guarantee data consistency.
Creating and Using Redis Cluster
The author has two servers, designed as follows:
| Server | Node | Port | Cluster Port |
|----------|------|-------|--------------|
| Server 1 | A | 7001 | 17001 |
| Server 1 | B | 7002 | 17002 |
| Server 1 | C | 7003 | 17003 |
| Server 2 | &A | 7001 | 17001 |
| Server 2 | &B | 7002 | 17002 |
| Server 2 | &C | 7003 | 17003 |
In practice, since the cluster nodes are automatically assigned when starting, it is the machine that determines which nodes are master and which are slaves. Thus, this is merely a design idea; the actual outcome will depend on the output results.
Deploying Three Master Nodes
On Server 1, create six directories:
cd /var
mkdir 7001 7002 7003 A B C
The directories 7001, 7002, and 7003 are named after respective ports to store the configuration files for nodes A, B, and C, while directories A, B, and C are for backing up data during Docker startup. If Docker is not being used, these directories are unnecessary.
In each of the three port directories, create a redis.conf file. The content for the port should reflect the specific port, as shown below:
port 7001
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
Make sure to change 7001 accordingly.
If only one server is available, use 7001-7006 along with directories A, B, C, D, E, and F.
Non-Docker
If not using Docker, Redis can be started as follows:
# Command
redis-server /var/redis/7001/redis.conf
# Binary file
./redis-server /var/redis/7001/redis.conf
# Repeat for others
Docker Installation
If the server has limited memory (for example, 1G or 2G), execute the following commands to eliminate Redis warnings.
Check the file /proc/sys/net/core/somaxconn. If the value is 128, change it to 1024.
Modify memory limits:
echo "vm.overcommit_memory=1" >> /etc/sysctl.conf
sysctl vm.overcommit_memory=1
There is also a kernel issue:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
For other issues, refer to this link: https://blog.csdn.net/a491857321/article/details/52006376
Pull the latest Redis image:
docker pull redis:latest
Execute the following three commands to start three Redis instances:
docker run -itd --name redisa --net=host -v /var/redis/A:/data -v /var/redis/7001:/etc/redis redis:latest redis-server /etc/redis/redis.conf --appendonly yes
docker run -itd --name redisb --net=host -v /var/redis/B:/data -v /var/redis/7002:/etc/redis redis:latest redis-server /etc/redis/redis.conf --appendonly yes
docker run -itd --name redisc --net=host -v /var/redis/C:/data -v /var/redis/7003:/etc/redis redis:latest redis-server /etc/redis/redis.conf --appendonly yes
Perform the same operations on the other server. If you are using a single server, you could alter the processes to create 6 containers instead.
Command explanation:
--net=host: Use host network, thus avoiding the need for -p to map ports.
-v /var/redis/B:/data: Data persistence.
/var/redis/7002:/etc/redis: Maps the physical machine directory to the container, where the configuration file resides.
redis-server: The command executed upon starting the container.
/etc/redis/redis.conf: A startup parameter indicating which configuration file to use with redis-server.
--appendonly yes: Always restart.
Creating the Cluster
If using Docker, execute the command to access the container on the first server:
docker exec -it redisa bash
Then create the cluster:
redis-cli --cluster create {ip}:7001 {ip}:7002 {ip}:7003 {ip}:7001 {ip}:7002 {ip}:7003 --cluster-replicas 1
Note: Please substitute the IP address accordingly.
After executing the command, the positions of the Redis instances will be automatically allocated. Type yes to agree to this allocation:
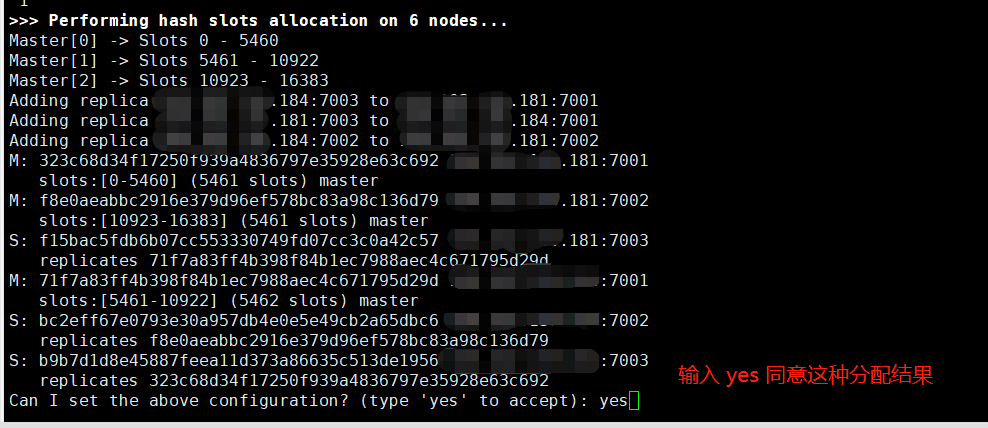
This automatic allocation is optimal as it prevents all three master nodes from being on the same server.
The cluster setup is complete, and we will begin learning some concepts in Redis, followed by using C# to create a program that connects to Redis.
Redis Introduction
Data Types in Redis
The commonly used data types in Redis are as follows:
- String
- Hash
- List
- Set
- Sorted Set
All data is stored in key-value format, with each piece of data having a unique key, and the aforementioned data types serving as values.
To delete a key, use the command: DEL {key}.
String
Strings are straightforward, with values being strings.
To set or access string-type data in Redis, use commands starting with SET or GET:
# Set String
SET a AAA
SET b 666
# Where a is the key and AAA is the value, no need to surround strings with ""
# ------
# Get String
GET a
# ------
# Get Multiple Strings
MGET a b
# Space-separated keys
Since Redis does not have value types, even without "", it will still be recognized as a string. It's better to include double quotes for readability.
Hash
A string is a key-value structure, while a hash is a collection of {key-value} pairs where the key is a string and the value can be of other types.
Thus, a Hash can be considered as a collection of key-value pairs, similar to a dictionary in C#, primarily used to store structured data.
Each hash in Redis can store up to 232 - 1 key-value pairs (over 4 billion).
Hash operations can be performed using commands such as HMSET, HMGET, and HGETALL.
For example, having this data:
id:1,
name:"痴者工良"
To store using hash:
# HMSET {key} {field1} {value1} {field2} {value2} ... ...
HMSET user id "1" name "痴者工良"
To query all key-value pairs of this hash table:
HGETALL user
To check a specific field within the hash table:
HGET user id
To delete a specific field:
HDEL user {field_name}
Lists
A list can contain multiple types of elements, primarily strings. A list is a linked list data structure implemented using a doubly linked list technique where elements closer to both ends are faster.
Elements can be added either at the head or the tail, and since lists function like stacks, they are ordered. Lists can also contain duplicate data, making them suitable for applications like message logs (queues), follower records, order records, etc.
Adding data to a list is done using:
LPUSH {key} {one_element_value}
For example:
LPUSH list a
LPUSH list b
LPUSH list c
There are many commands for lists; refer to the documentation for details.
Set
Lists are ordered, while sets are unordered. Sets do not allow duplicate data.
Use cases include recording unique website access IPs and different types of flowers in a florist's shop.
A set is a collection of string elements and can only store strings.
To add an element to a set, use the SADD command:
SADD set a
SADD set b
SADD set c
SADD set a b c
Sorted Set
Sorted sets function similarly to sets but with sorted elements based on their values in ascending order.
Like sets, a sorted set can only add strings.
ZADD ss 2 a
ZADD ss 1 b
ZADD ss 4 z
To query:
ZRANGE ss 0 10 WITHSCORES
As a reminder, please ensure to set a password for Redis in a production environment.

文章评论