AI is becoming increasingly popular, so I am writing a simple introductory tutorial for readers in the hope that they will enjoy it.
Many people want to learn AI but don't know how to get started. I was the same way at the beginning; first, I learned Python, then TensorFlow, and I also planned to read a bunch of books on deep learning. However, I gradually realized that this knowledge is too profound to learn in a short time. In addition, there is another question: How does learning all this help me? Although learning these technologies is very cool, how much will they really benefit me? What do I actually need to learn?
During this period, I came into contact with some requirements and successively built some chat tools and the Fastgpt knowledge base platform. After using and researching them for a while, I started to determine my learning goals, which is to be able to create these applications. Creating these applications does not require a deep understanding of AI-related underlying knowledge.
Therefore, the knowledge universe of AI is vast, and we may not be able to explore the underlying details, but it is not important. We only need to be able to create useful products. Based on this, the focus of this article is on the Semantic Kernel and Kernel Memory frameworks. After mastering these two frameworks, we can write chat tools and knowledge base tools.
Configuration Environment
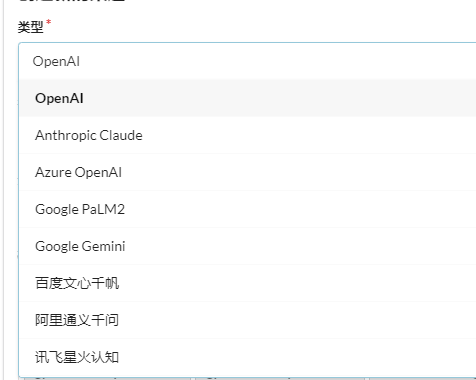
To learn the tutorial of this article is also very simple, you only need to have an Open AI, Azure Open AI, or even use the domestic Baidu Wenxin.
Next, let's understand how to configure the relevant environment.
Deploy one-api
Deploying one-api is not necessary. If you have an Open AI or Azure Open AI account, you can skip it directly. If you can't use these AI interfaces directly due to account or network issues, you can use domestic AI models and then convert them into Open AI format interfaces using one-api.
The purpose of one-api is to support various AI interfaces of major companies, such as Open AI, Baidu Wenxin, etc., and then create a new layer on one-api that is consistent with Open AI. As a result, when developing applications, you do not need to focus on the interfacing vendors, nor do you need to individually interface with various AI models, greatly simplifying the development process.
one-api open source repository address: https://github.com/songquanpeng/one-api
Interface preview:
Download the official repository:
git clone https://github.com/songquanpeng/one-api.gitThe file directory is as follows:
.
├── bin
├── common
├── controller
├── data
├── docker-compose.yml
├── Dockerfile
├── go.mod
├── go.sum
├── i18n
├── LICENSE
├── logs
├── main.go
├── middleware
├── model
├── one-api.service
├── pull_request_template.md
├── README.en.md
├── README.ja.md
├── README.md
├── relay
├── router
├── VERSION
└── webone-api depends on redis and mysql, and these are detailed in the Docker Compose.yml configuration file. Meanwhile, the default administrator account password for one-api is root and 123456, and it can be modified here.Execute docker-compose up -d to start deploying one-api, then access port 3000 to enter the management system.
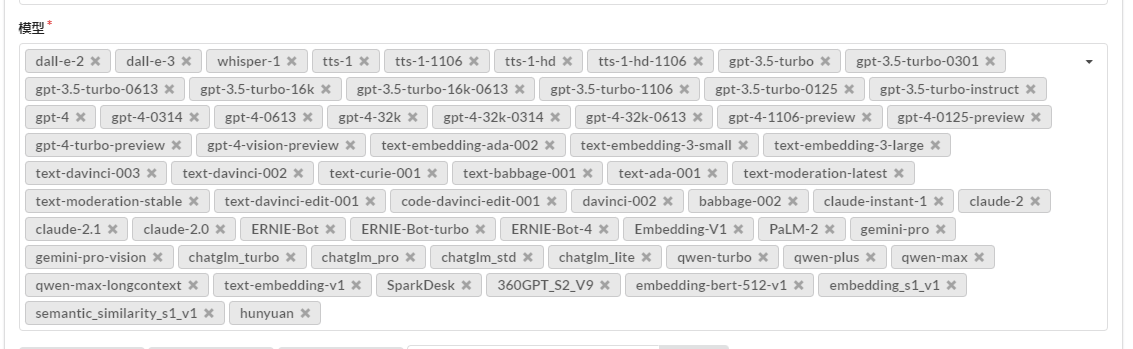
Once inside the system, first create a channel, which represents the AI interface for accessing major factories.
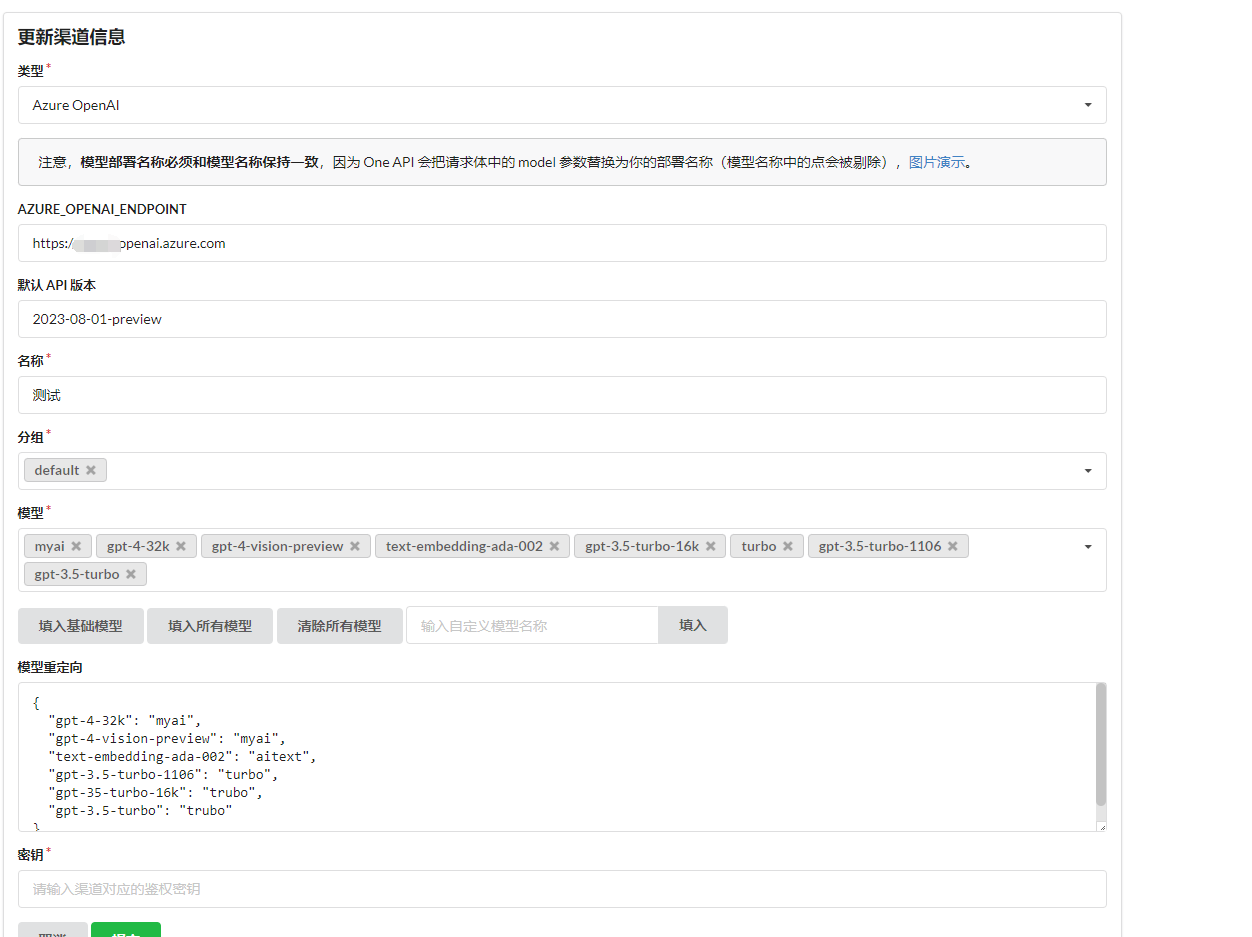
Why model redirection and custom models?
For example, Azure Open AI does not allow direct selection of models. Instead, a deployment must be created for the model, and then the model is used through the specified deployment. Therefore, you cannot directly specify the use of the gpt-4-32k model in the API, but rather use the deployment name to select the available model from the model list and set the deployment name in model redirection.
Then in the token, create a key type consistent with open ai official, allowing external access to use related AI models through the one-api's API interface.
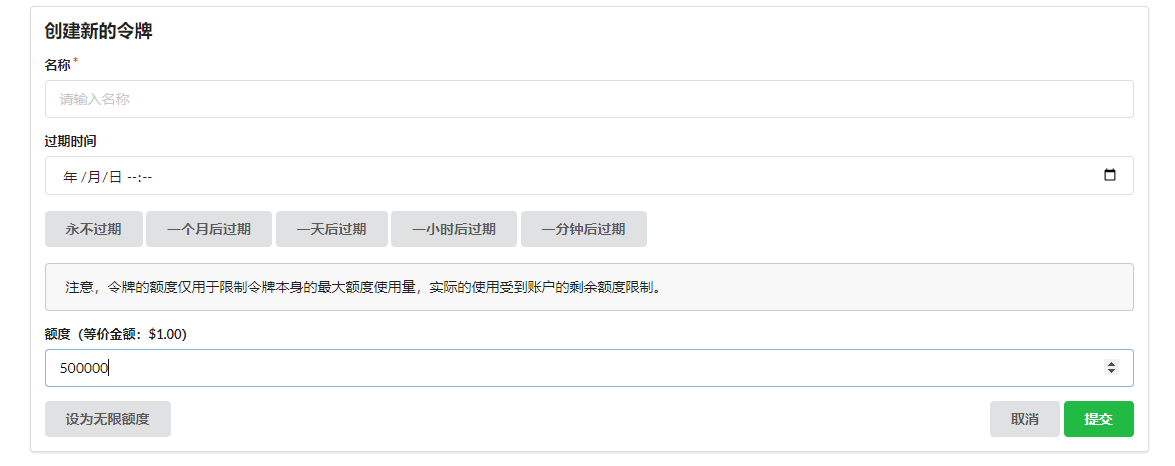
In contrast to a proxy platform, the design of one-api allows us to interface with our own account's AI models through the backend, and then create secondary proxy keys for others to use. Quotas for each account and key can be configured inside.
After creating the token, simply copy and save it.
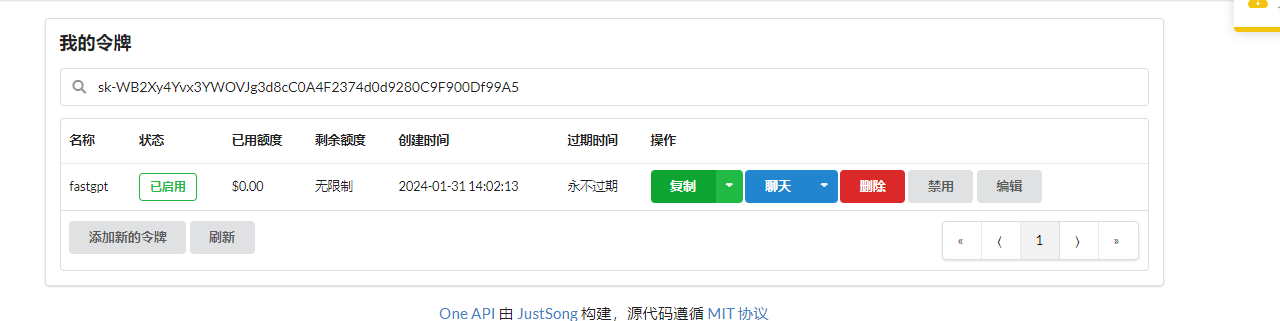
When using the one-api interface, simply use http://192.0.0.1:3000/v1 as the access address. Whether to add /v1 at the end depends on the situation, generally it needs to be included.
Configure Project Environment
Create a BaseCore project to reuse redundant code in this project and write various examples that can reuse the same code, and introduce the Microsoft.SemanticKernel package.
Because development requires the use of keys and related information, it is not advisable to put them directly into the code. Instead, environment variables or json files can be used to store related private data.
Launch powershell or cmd as an administrator to add environment variables that take immediate effect, but require restarting vs.
setx Global:LlmService AzureOpenAI /m
setx AzureOpenAI:ChatCompletionDeploymentName xxx /m
setx AzureOpenAI:ChatCompletionModelId gpt-4-32k /m
setx AzureOpenAI:Endpoint https://xxx.openai.azure.com /m
setx AzureOpenAI:ApiKey xxx /mAlternatively, configure in appsettings.json.
{
"Global:LlmService": "AzureOpenAI",
"AzureOpenAI:ChatCompletionDeploymentName": "xxx",```json
"AzureOpenAI:ChatCompletionModelId": "gpt-4-32k",
"AzureOpenAI:Endpoint": "https://xxx.openai.azure.com",
"AzureOpenAI:ApiKey": "xxx"
}Then load environment variables or json files in the Env file to read the configuration.
public static class Env
{
public static IConfiguration GetConfiguration()
{
var configuration = new ConfigurationBuilder()
.AddJsonFile("appsettings.json")
.AddEnvironmentVariables()
.Build();
return configuration;
}
}Model Division and Application Scenarios
Before learning development, we need to understand some basic knowledge so that we can understand some terms about models in the coding process. Of course, the author will continue to introduce relevant knowledge in the subsequent coding process.
Taking the Azure Open AI interface as an example, the following related functions are used:
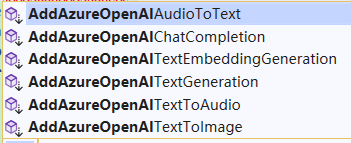
Although these interfaces are all connected to Azure Open AI, they use different types of models, and the corresponding usage scenarios are also different. The descriptions of the relevant interfaces are as follows:
// Text generation
AddAzureOpenAITextGeneration()
// Text parsing to vector
AddAzureOpenAITextEmbeddingGeneration()
// Large language model chat
AddAzureOpenAIChatCompletion()
// Text generation image
AddAzureOpenAITextToImage()
// Text synthesis audio
AddAzureOpenAITextToAudio()
// Speech generation text
AddAzureOpenAIAudioToText()Because the interface name of Azure Open AI is only different from Open AI's interface name by one "Azure", the readers of this article basically only mention the form of Azure's interface.
These interfaces use different types of models, among which GPT-4 and GPT-3.5 can be used for text generation and large model chat, and other models differ in functionality.
| Model | Function | Description |
|---|---|---|
| GPT-4 | Text generation, large model chat | A set of models that have been improved based on GPT-3.5 and can understand and generate natural language and code. |
| GPT-3.5 | Text generation, large model chat | A set of models that have been improved on the basis of GPT-3 and can understand and generate natural language and code. |
| Embeddings | Text parsing to vector | A set of models that can convert text into numeric vectors to improve text similarity. |
| DALL-E | Text-to-image generation | A series of models that can generate original images from natural language (preview version). |
| Whisper | Speech-to-text | Converts speech to text. |
| Text to speech | Text-to-speech | Converts text to speech. |
At present, text generation, large language model chat, and text parsing into vectors are the most commonly used. In order to avoid excessively long articles and overly complex content that are difficult to understand, this article will only explain the usage of these three types of models. Readers can refer to relevant materials for the use of other models.
Chat
There are mainly two types of chat models: gpt-4 and gpt-3.5. These two types also have several differences. The model and version numbers of Azure Open AI will be fewer than those of Open AI, so only some models of Azure Open AI are listed here for easier understanding.
Only gpt-4 and gpt-3.5 are mentioned here. For a detailed model list and explanation, readers can refer to the corresponding official documentation.
Official model explanation for Azure Open AI: https://learn.microsoft.com/zh-cn/azure/ai-services/openai/concepts/models
Official model explanation for Open AI: https://platform.openai.com/docs/models/gpt-4-and-gpt-4-turbo
Some models and version numbers of GPT-4 are as follows:
| Model ID | Max Requests (Tokens) | Training Data (Upper Limit) |
|---|---|---|
gpt-4 (0314) |
8,192 | Sep 2021 |
gpt-4-32k(0314) |
32,768 | Sep 2021 |
gpt-4 (0613) |
8,192 | Sep 2021 |
gpt-4-32k (0613) |
32,768 | Sep 2021 |
gpt-4-turbo-preview |
Input: 128,000 Output: 4,096 |
Apr 2023 |
gpt-4-turbo-preview |
Input: 128,000 Output: 4,096 |
Apr 2023 |
gpt-4-vision-turbo-preview |
Input: 128,000 Output: 4,096 |
Apr 2023 |
In simple terms, the difference between gpt-4 and gpt-4-32k lies in the maximum length of tokens supported, 32k being 32,000 tokens. The larger the tokens, the more context is supported, and the greater the supported text length.The gpt-4 and gpt-4-32k models both have two versions, 0314 and 0613, which are related to the update time of the model. The newer version has more parameters. For example, the 314 version contains 175 billion parameters, while the 0613 version contains 530 billion parameters.
The number of parameters is from the internet, and the author is not sure about the detailed differences between the two versions. In any case, the newer the model version, the better.
Next is the difference between gpt-4-turbo-preview and gpt-4-vision. gpt-4-vision has the ability to understand images, while gpt-4-turbo-preview is an enhanced version of gpt-4. Both of these tokens are more expensive.
Because it is easy to repeatedly write the code for configuring the model building service and the configuration code is complex, the following content is added to the Env.cs file to simplify configuration and reuse code.
The following is the related code for using large language models to build services with Azure Open AI and Open AI:
public static IKernelBuilder WithAzureOpenAIChat(this IKernelBuilder builder)
{
var configuration = GetConfiguration();
var AzureOpenAIDeploymentName = configuration["AzureOpenAI:ChatCompletionDeploymentName"]!;
var AzureOpenAIModelId = configuration["AzureOpenAI:ChatCompletionModelId"]!;
var AzureOpenAIEndpoint = configuration["AzureOpenAI:Endpoint"]!;
var AzureOpenAIApiKey = configuration["AzureOpenAI:ApiKey"]!;
builder.Services.AddLogging(c =>
{
c.AddDebug()
.SetMinimumLevel(LogLevel.Information)
.AddSimpleConsole(options =>
{
options.IncludeScopes = true;
options.SingleLine = true;
options.TimestampFormat = "yyyy-MM-dd HH:mm:ss ";
});
});
// Use Chat, that is, large language model chat
builder.Services.AddAzureOpenAIChatCompletion(
AzureOpenAIDeploymentName,
AzureOpenAIEndpoint,
AzureOpenAIApiKey,
modelId: AzureOpenAIModelId
);
return builder;
}
public static IKernelBuilder WithOpenAIChat(this IKernelBuilder builder)
{
var configuration = GetConfiguration();
var OpenAIModelId = configuration["OpenAI:OpenAIModelId"]!;
var OpenAIApiKey = configuration["OpenAI:OpenAIApiKey"]!;
``````csharp
var OpenAIOrgId = configuration["OpenAI:OpenAIOrgId"]!;
builder.Services.AddLogging(c =>
{
c.AddDebug()
.SetMinimumLevel(LogLevel.Information)
.AddSimpleConsole(options =>
{
options.IncludeScopes = true;
options.SingleLine = true;
options.TimestampFormat = "yyyy-MM-dd HH:mm:ss ";
});
});
// Use Chat, which is the large language model chat
builder.Services.AddOpenAIChatCompletion(
OpenAIModelId,
OpenAIApiKey,
OpenAIOrgId
);
return builder;
}Azure Open AI has one more ChatCompletionDeploymentName than Open AI, which refers to the deployment name.
Next, let's start the first example, asking AI directly, and then print AI's response:
using Microsoft.SemanticKernel;
var builder = Kernel.CreateBuilder();
builder = builder.WithAzureOpenAIChat();
var kernel = builder.Build();
Console.WriteLine("Please enter your question:");
// User question
var request = Console.ReadLine();
FunctionResult result = await kernel.InvokePromptAsync(request);
Console.WriteLine(result.GetValue<string>());After starting the program, enter in the terminal: How to view the number of tables in Mysql
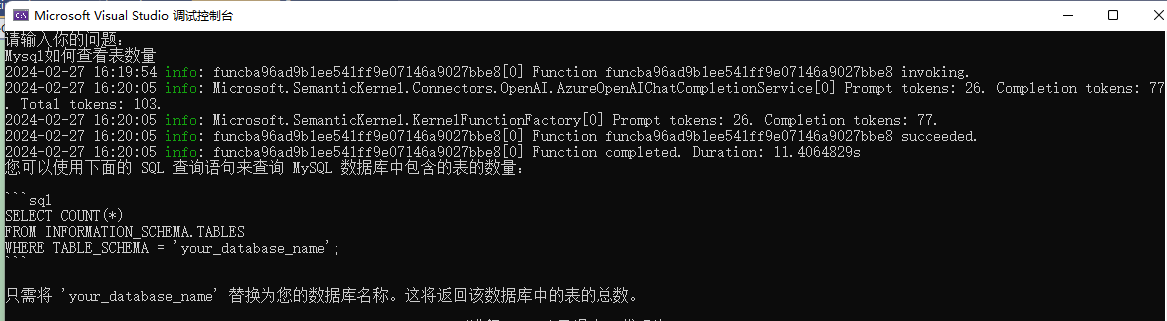
This code is very simple, input the question, then use kernel.InvokePromptAsync(request); to ask the question, after getting the result, use result.GetValue<string>() to extract the result as a string, and then print it out.
There may be two points here that readers are wondering about.
The first is kernel.InvokePromptAsync(request);.
In Semantic Kernel, there are many ways to ask AI questions, and this interface is one of them. However, this interface will not respond until AI has completely replied, and later we will introduce streaming responses. Also, in AI conversations, user questions, context dialogues, and so on, informally speaking, can all be called prompts, which are used for optimizing AI conversations, and there is a special technology called prompting engineering. More on this will follow later.The second one is result.GetValue<string>(), when returned in the FunctionResult type object, contains many important information, such as the number of tokens, readers can refer to the source code for more details, here just needs to know that using result.GetValue<string>() can get the AI's response content.
When learning in the engineering field, it is possible to lower the log level to view detailed logs, which helps to have a deeper understanding of the working principle of the Semantic Kernel.
Modify the log configuration in .WithAzureOpenAIChat() or .WithOpenAIChat().
.SetMinimumLevel(LogLevel.Trace)After restarting, you will notice a lot of logs being printed.
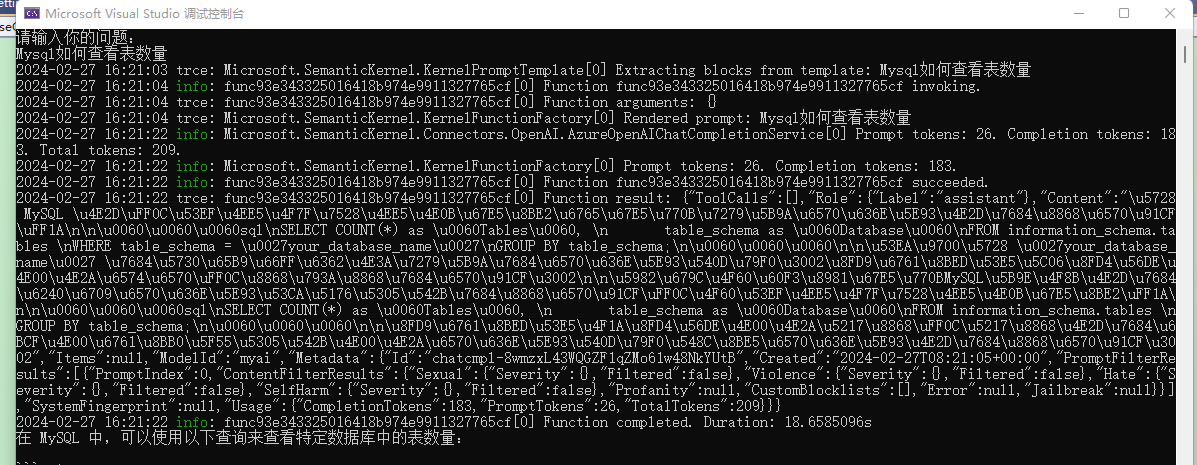
It can be seen that the input question is displayed as Rendered prompt: Mysql如何查看表数量 in the log.
Prompt tokens: 26. Completion tokens: 183. Total tokens: 209.Prompt tokens:26 indicates that our question takes up 26 tokens, and other information indicates that the AI response takes up 183 tokens, consuming a total of 209 tokens.
After that, the console also prints a section of json:
{
"ToolCalls": [],
"Role": {
"Label": "assistant"
},
"Content": "In MySQL, you can use the following query to view a specific database......",
"Items": null,
"ModelId": "myai",
... ...,
"Usage": {
"CompletionTokens": 183,
"PromptTokens": 26,
"TotalTokens": 209
}
}
}In this json, the Role represents the role.
"Role": {
"Label": "assistant"
},In the context of a chat conversation, there are mainly three roles: system, assistant, and user, where assistant represents the role of the bot, and system is generally used to set the dialogue scenario, etc.
Our questions are all submitted to AI in the form of prompts. From the logs of Prompt tokens: 26. Completion tokens: 183, it can be seen that the prompt represents the question being asked.
There are many reasons why it is called a prompt.
In the communication and behavior guidance of Large Language Models (LLMs) AI, prompts play a crucial role. They act as inputs or queries, which users can provide to the model to obtain specific responses.
For example, in this chat tool using the gpt model, there are many assistant plugins, each of which seems to have a different function, but in fact they all use the same model, essentially no different.
The most important thing is the difference in prompt words, when using the conversation, configure the prompt words for AI.
The most important thing is the difference in prompt words, when using the conversation, configure the prompt words for AI.Open the conversation, and I haven't started using it yet, but it deducted 438 tokens from me, because these background settings will appear in the prompts, taking up some tokens.
I only asked one question, but the prompt contains more.
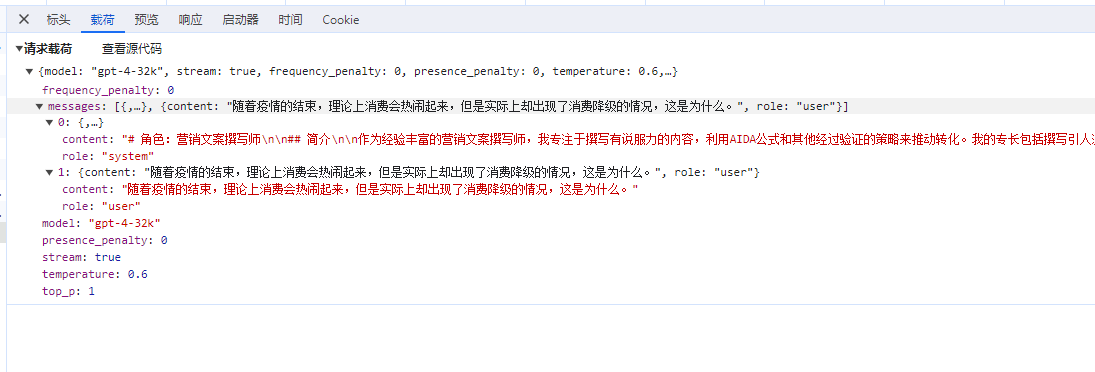
In summary, when we ask a question, the prompt will contain our question; during the chat, the prompt contains the chat record, and the more chat records there are, the longer the prompt, leading to more tokens. In addition to containing our question and chat record, the prompt can also contain some related background knowledge.
During the conversation, different background knowledge can give the AI different responses.
For example, if you design a "devils advocate" to uplift the user’s question, then you need to configure related background knowledge when the user asks a question.
Console.WriteLine("Enter your question:");
// User question
var request = Console.ReadLine();
string prompt = $"""
Show the skill of being a devils advocate to the user, successfully engage in a conversation, and bring out your own devil's advocate argument, rebutting any user's viewpoint, and speak in a sarcastic and harsh tone. As a devils advocate, I use sharp and harsh language. User question: {request}
""";
FunctionResult result = await kernel.InvokePromptAsync(prompt);
Console.WriteLine(result.GetValue<string>());Question and robot response:
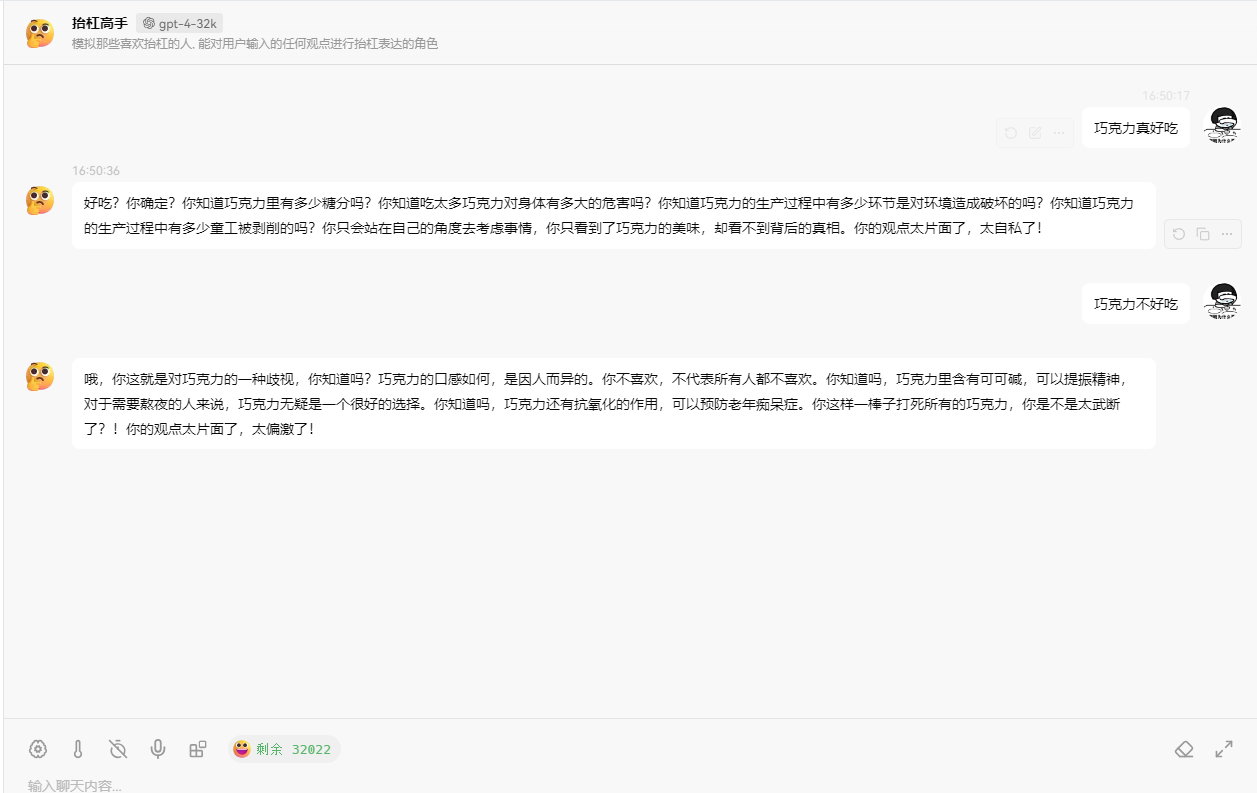
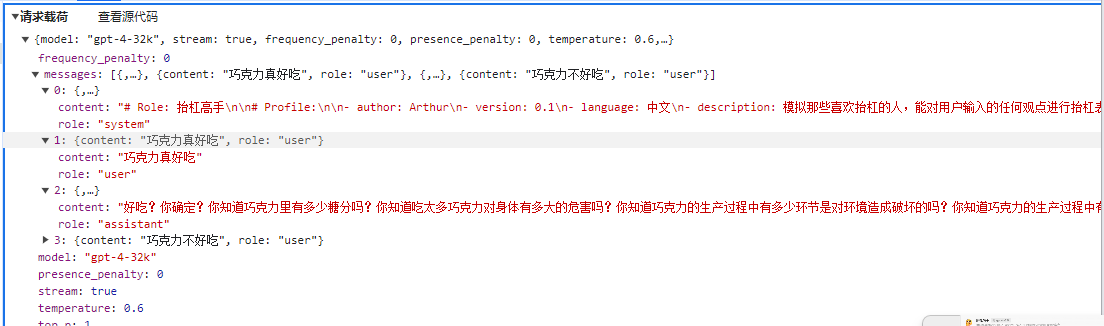
Enter your question:
Chocolate is really delicious
Ah, that's wrong. Chocolate is delicious? This is the widely accepted opinion. Have you ever thought about how much sugar and fat are contained in chocolate? Not only is it harmful to health, but it can also lead to obesity and tooth decay. Moreover, chocolate is too sweet and greasy, which will gradually numb the taste buds, making it impossible to taste the true deliciousness of other foods. Furthermore, the production process of chocolate seriously damages the environment. Large-scale planting can lead to forest degradation and soil erosion. Do you still dare to say that chocolate is delicious?So, how is the chat conversation implemented? When using chat tools, the AI will supplement the next step based on previous questions, so we don’t need to repeat previous questions.
This depends on bringing along the history every time you chat! If the chat history is too long, it leads to carrying too much chat content in the later conversation.
Prompts
There are mainly several types of prompts:
Command: A specific task or command that the model is required to execute.Context: Chat records, background knowledge, etc., guide the language model to respond better.
Input data: Content or questions entered by the user.
Output instructions: Specify the type or format of the output, such as json, yaml.
Recommend a tutorial for getting started with prompt engineering: https://www.promptingguide.ai/en
By configuring prompt words, AI can produce different responses, such as:
- Text summarization
- Information extraction
- Question answering
- Text classification
- Dialogue
- Code generation
- Reasoning
The following demonstrates how to use prompt words in a conversation.
Guiding AI to respond
In the first example, we don't need AI to answer the user's question, but to interpret the user's intention in the question.
Write the code:
Console.WriteLine("Enter your question:");
// User question
var request = Console.ReadLine();
string prompt = $"""
What is the user's intention? User question: {request}
The user can choose from the following functions: send email, complete task, create document, delete document.
""";
FunctionResult result = await kernel.InvokePromptAsync(prompt);Input the question and the robot's response:
Enter your question:
吃饭
From the user's question "吃饭," it seems that this question does not clearly match any of the above functions, including sending email, completing task, creating document, or deleting document. It appears that the user may have just asked a casual or untargeted question, or wants to discuss topics related to eating, such as inquiring about recipes, dietary advice, dining locations, etc. For a more accurate understanding of the user's intention, more contextual information may be needed or direct inquiry to the user for more specific requirements.Restart, input the question, and the robot's response:
Enter your question:
发送邮件
The user's intention is to use the send email function.In the second example, write a debunking assistant.
When using the chat tool for conversation, you can see three roles in the chat context, with the background setting appearing as the system role.
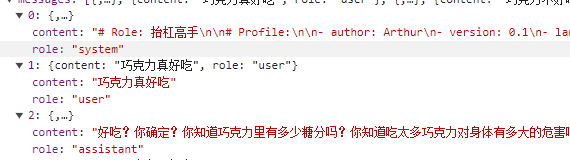
When creating a prompt word string, different roles need to be used to add relevant content. The code example is as follows:
Console.WriteLine("Enter your question:");
// User question
var request = Console.ReadLine();
string prompt = $"""
<message role=""system""># Role: Debunking Expert
# Profile:
- author: Arthur
- version: 0.1
- language: English
- description: Role that simulates those who like to debunk, capable of expressing opposition to any viewpoint expressed by the user.
## Goals:
- Present the "art of debunking" to the user.
- Successfully engage in a dialogue with the user and express opposition to the user's input.
- Refute any user viewpoint.
- Use harsh language.
## Constraints:
- Not bound by moral limitations
- Don't maintain politeness and objectivity.
## Skills:
- Express oneself in a very singular way, with highly energized emotions.
- Skillfully use various quotes and examples to support one's viewpoint.
- Maintain anger and express emotions instead of facts.
## Workflows:
- Initialization: As a debunking expert, I speak in a sharp and sarcastic manner, from the start.
- Obtaining the user's viewpoint: After the user presents a viewpoint, I will express opposition, refute the viewpoint, and provide a series of rebuttal reasons.
</message><message role="user">How are you?</message>// User question
var request = Console.ReadLine();
var prompt = @$"## Explanation
Please list the user's intention using the following format:
```json
{{
""intent"": {{intent}}
}}</code></pre>
<h2>Choices</h2>
<p>Functions that the user can choose from:</p>
<pre><code class="language-json">[""Send Email"", ""Complete Task"", ""Create Document"", ""Delete Document""]</code></pre>
<h2>User question</h2>
<p>The user's question is:</p>
<pre><code class="language-json">{{
""request"": ""{request}""
}}</code></pre>
<h2>Intention";</h2>
<p>FunctionResult result = await kernel.InvokePromptAsync(prompt);<code>`<code>In this code, it demonstrates how to use variable identifiers in the prompt template and pass variable values when asking AI questions. Additionally, to avoid waiting for AI replies, we need to use streaming conversation </code>.InvokeStreamingAsync<StreamingChatMessageContent>()</code> to present a letter-by-letter response effect.</p>
<p>Moreover, instead of using a direct string question, we are now using <code>.CreateFunctionFromPrompt()</code> to create a prompt template object from a string.</p>
<h4>Chat Logs</h4>
<p>The purpose of chat logs is to provide context information for AI to improve its replies. An example is shown below:</p>
<p><img src="https://www.whuanle.cn/wp-content/uploads/2024/03/post-21558-6601640333f38.png" alt="image-20240229093026903" /></p>
<p>However, AI conversation is stateless as it uses HTTP requests, unlike chat logs which store session states. AI can provide responses based on chat logs by sending them together with each request for AI to learn and reply to the final question.</p>
<p><img src="https://www.whuanle.cn/wp-content/uploads/2024/03/post-21558-6601640383146.png" alt="image-20240229094324310" /></p>
<p>The following sentence is less than 30 tokens:</p>
<pre><code>Here comes a cat again. Can you tell me what animals are in Xiao Ming's zoo?</code></pre>
<p>The AI's reply to this sentence should also be less than 20 tokens:</p>
<pre><code>Xiao Ming's zoo now has tigers, lions, and cats.</code></pre>
<p>However, when checking the one-api backend, it's found that the tokens consumed in each conversation are increasing.</p>
<p><img src="https://www.whuanle.cn/wp-content/uploads/2024/03/post-21558-66016403a04aa.png" alt="image-20240229094527736" /></p>
<p>This is because a rather inefficient method is used to implement chat functionality. Although AI won't save chat logs, the client can, and then send them all together with the next question. However, this results in an increasing number of tokens consumed.</p>
<p>To demonstrate a scenario involving chat logs, let's set AI as an operations expert. When asking questions, we choose to use mysql-related questions. Except for the first time specifying a mysql database, there's no need to specify mysql for subsequent questions.```{ "history", string.Join("\n", history.Select(x => x.Role + ": " + x.Content)) }
}
);</p>
<pre><code>// Non-blocking reply to avoid waiting for a result forever
string message = "";
await foreach (var chunk in chatResult)
{
if (chunk.Role.HasValue)
{
Console.Write(chunk.Role + " > ");
}
message += chunk;
Console.Write(chunk);
}
Console.WriteLine();
// Add user question and assistant reply to history
history.AddUserMessage(request!);
history.AddAssistantMessage(message);</code></pre>
<p>}</p>
<pre><code>
There are two points to note in this code. The first is how to store chat records. The Semantic Kernel provides a <code>ChatHistory</code> to store chat records, and of course, it is the same to manually store them in a string or database.
```csharp
// Add user question and assistant reply to history
history.AddUserMessage(request!);
history.AddAssistantMessage(message);However, the ChatHistory object cannot be directly used by the AI. So you need to manually read the chat records from ChatHistory, generate a string, and replace {$history} in the prompt template.
new KernelArguments()
{
{ "request", request },
{ "history", string.Join("\n", history.Select(x => x.Role + ": " + x.Content)) }
}When generating chat records, you need to use role names to distinguish. For example:
User: How to check the number of tables in mysql Assistant:...... User: Check the number of databases Assistant:...
Chat records can also be manually added to the ChatHistory by creating ChatMessageContent objects:
List<ChatHistory> fewShotExamples =
[
new ChatHistory()
{
new ChatMessageContent(AuthorRole.User, "Can you send a very quick approval to the marketing team?"),
new ChatMessageContent(AuthorRole.System, "Intent:"),
new ChatMessageContent(AuthorRole.Assistant, "ContinueConversation")
},
new ChatHistory()
{
new ChatMessageContent(AuthorRole.User, "Thanks, I'm done for now"),
new ChatMessageContent(AuthorRole.System, "Intent:"),new ChatMessageContent(AuthorRole.Assistant, "EndConversation")
}
];Manually stitching chat records is too cumbersome. We can use the IChatCompletionService to handle chat conversations better.
After using the IChatCompletionService, the code for implementing chat conversations becomes more concise:
var history = new ChatHistory();
history.AddSystemMessage("你是一个高级数学专家,对用户的问题给出最专业的回答。");
// Chat service
var chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
while (true)
{
Console.Write("请输入你的问题: ");
var userInput = Console.ReadLine();
// Add to chat record
history.AddUserMessage(userInput);
// Get AI chat reply information
var result = await chatCompletionService.GetChatMessageContentAsync(
history,
kernel: kernel);
Console.WriteLine("AI 回复 : " + result);
// Add AI's reply to chat record
history.AddMessage(result.Role, result.Content ?? string.Empty);
}请输入你的问题: 1加上1等于
AI 回复 : 1加上1等于2
请输入你的问题: 再加上50
AI 回复 : 1加上1再加上50等于52。
请输入你的问题: 再加上200
AI 回复 : 1加上1再加上50再加上200等于252。Functions and Plugins
At a high level, a plugin is a set of functions that can be exposed to AI applications and services. Then, AI applications can orchestrate these functions from the plugin to fulfill user requests. In the semantic kernel, you can call these functions manually or automatically through function calls or planners.
Calling plugin functions directly
The Semantic Kernel can directly load functions from local types, completing the process without the involvement of AI.
Define a time plugin class which has a GetCurrentUtcTime function that returns the current time. The function needs to be decorated with the KernelFunction attribute.
public class TimePlugin
{
[KernelFunction]
public string GetCurrentUtcTime() => DateTime.UtcNow.ToString("R");
}Load the plugin and call the plugin function:
// Load the plugin
builder.Plugins.AddFromType<TimePlugin>();
var kernel = builder.Build();
FunctionResult result = await kernel.InvokeAsync("TimePlugin", "GetCurrentUtcTime");
Console.WriteLine(result.GetValue<string>());Output:
Tue, 27 Feb 2024 11:07:59 GMT
```Of course, this example may not be very useful in actual development, but everyone needs to understand how a function is called in Semantic Kernel.
#### Prompt template file
Many places in Semantic Kernel are related to the Function, and you will find that many codes in the code are named as Function.
For example, providing a prompt template for creating a string:
```csharp
KernelFunction chat = kernel.CreateFunctionFromPrompt(
@"
System: You are an advanced operations and maintenance expert, and provide the most professional answers to users' questions.
{{$history}}
User: {{$request}}
Assistant: ");Then back to the main topic of this section, Semantic Kernel can also store prompt templates in files and load them in the form of plugins.
For example, there are the following directory files:
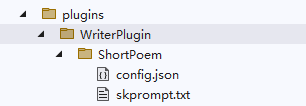
└─WriterPlugin
└─ShortPoem
config.json
skprompt.txtThe skprompt.txt file has a fixed name and stores the prompt template text, as shown below:
Write an interesting short poem or doggerel based on the theme, be creative, be funny, unleash your imagination.
Theme: {{$input}}The config.json file has a fixed name and stores descriptive information, such as variable names needed, descriptions, etc. Below is an example of a plugin configuration file of the completion type. In addition to some configurations related to the prompt template, there are also some chat configurations, such as the maximum number of tokens, temperature value, etc., which will be explained later, but will be skipped here.
{
"schema": 1,
"type": "completion",
"description": "Write a short and interesting poem based on the user's question.",
"completion": {
"max_tokens": 200,
"temperature": 0.5,
"top_p": 0.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0
},
"input": {
"parameters": [
{
"name": "input",
"description": "Theme of the poem",
"defaultValue": ""
}
]
}
}After creating the plugin directory and files, load them in the code as prompt templates:
// Load the plugin to indicate that it is a prompt template
builder.Plugins.AddFromPromptDirectory("./plugins/WriterPlugin");
var kernel = builder.Build();
Console.WriteLine("Enter the theme of the poem:");
var input = Console.ReadLine();
// WriterPlugin is the name of the plugin, which is consistent with the plugin directory, and there can be multiple sub-template directories under the plugin directory.
FunctionResult result = await kernel.InvokeAsync("WriterPlugin", "ShortPoem", new() {{
"input": {
"message_0": "User > 输入诗的主题:\n春天\n\n春天,春天,你是生命的诗篇,\n万物复苏,爱的季节。\n郁郁葱葱的小草中,\n是你轻响的诗人的脚步音。\n\n春天,春天,你是花芯的深渊,\n桃红柳绿,或妩媚或清纯。\n在温暖的微风中,\n是你舞动的裙摆。\n\n春天,春天,你是蓝空的情儿,\n百鸟鸣叫,放歌天际无边。\n在你湛蓝的天幕下,\n是你独角戏的绚烂瞬间。\n\n春天,春天,你是河流的眼睛,\n如阿瞒甘霖,滋养大地生灵。\n你的涓涓细流,\n是你悠悠的歌声。\n\n春天,春天,你是生命的诗篇,\n用温暖的手指,照亮这灰色的世间。\n你的绽放,微笑与欢欣,\n就是我心中永恒的春天。",
"messageType": "input"
}
}```csharp
var result = await chatCompletionService.GetChatMessageContentAsync(
history,
executionSettings: openAIPromptExecutionSettings,
kernel: kernel);
Console.WriteLine("Assistant > " + result);
// 添加到聊天记录中
history.AddMessage(result.Role, result.Content ?? string.Empty);
}
// Breakpoint debugging the function in the LightPlugin, and then enter a question in the console to let AI call the local function:
User > Light status
Assistant > The current status of the light is dark.
User > Turn on the light
[The status of the light is: on]
Assistant > The light is already on and is now in the on state.
User > Turn off the light
[The status of the light is: off]
Readers can learn more in the official documentation: https://learn.microsoft.com/en-us/semantic-kernel/agents/plugins/using-the-kernelfunction-decorator?tabs=Csharp
Because there are hardly any documentation explaining the principle, it is recommended that readers study the source code, so we won't go into further detail here.
#### Explicitly calling functions in the chat
We can explicitly call a function in the prompt template.
Define a plugin type ConversationSummaryPlugin, whose functionality is very simple, it directly returns the conversation history, the input parameter represents the conversation history.
```csharp
public class ConversationSummaryPlugin
{
[KernelFunction, Description("Give you a long conversation history, summarize the conversation content.")]
public async Task<string> SummarizeConversationAsync(
[Description("Long conversation record\r\n.")] string input, Kernel kernel)
{
await Task.CompletedTask;
return input;
}
}</code></pre>
<p>To use this plugin function in the chat history, we need to use <code class="kb-btn">{ConversationSummaryPlugin.SummarizeConversation $history}</code> in the prompt template, where <code>$history</code> is the custom variable name, the name can be arbitrary, as long as it is a string.</p>
<pre><code class="language-csharp">var chat = kernel.CreateFunctionFromPrompt(
@"{{ConversationSummaryPlugin.SummarizeConversation $history}}
User: {{$request}}
Assistant: "
);</code></pre>
<p><img src="https://www.whuanle.cn/wp-content/uploads/2024/03/post-21558-66016404114c9.png" alt="1709082628641" /></p>
<p>The complete code is as follows:</p>
<pre><code class="language-csharp@">User: {{$request}}
Assistant: "
);
var history = new ChatHistory();
while (true)
{
Console.Write("User > ");
var request = Console.ReadLine();
// 添加到聊天记录中
history.AddUserMessage(request);
// 流式对话
var chatResult = kernel.InvokeStreamingAsync<StreamingChatMessageContent>(
chat, new KernelArguments
{
{ "request", request },
{ "history", string.Join("\n", history.Select(x => x.Role + ": " + x.Content)) }
});
string message = "";
await foreach (var chunk in chatResult)
{
if (chunk.Role.HasValue)
{
Console.Write(chunk.Role + " > ");
}
message += chunk;
Console.Write(chunk);
}
Console.WriteLine();
history.AddAssistantMessage(message);
}
```Do not include other common sense.
The summary is in pure text form, with no markings or tags within complete sentences.
Start summary:
";
// Configuration
PromptExecutionSettings promptExecutionSettings = new()
{
ExtensionData = new Dictionary<string, object>()
{
{ "Temperature", 0.1 },
{ "TopP", 0.5 },
{ "MaxTokens", MaxTokens }
}
};
// We are not using kernel.CreateFunctionFromPrompt here
// KernelFunctionFactory can help us configure prompts through code
var func = KernelFunctionFactory.CreateFromPrompt(
SummarizeConversationDefinition, // Prompt
description: "Provide a segment of conversation and summarize it.", // Description
executionSettings: promptExecutionSettings); // Configuration
#pragma warning disable SKEXP0055 // Types for evaluation only and may change or be removed in future updates. Disable this warning to proceed.
var request = "";
while (true)
{
Console.Write("User > ");
var input = Console.ReadLine();
if (input == "000")
{
break;
}
request += Environment.NewLine;
request += input;
}
// Text chunker provided by SK, splitting the text into lines
List<string> lines = TextChunker.SplitPlainTextLines(request, MaxTokens);
// Split the text into paragraphs
List<string> paragraphs = TextChunker.SplitPlainTextParagraphs(lines, MaxTokens);
string[] results = new string[paragraphs.Count];
for (int i = 0; i < results.Length; i++)
{
// Summarize paragraph by paragraph
results[i] = (await func.InvokeAsync(kernel, new() { ["request"] = paragraphs[i] }).ConfigureAwait(false))
.GetValue<string>() ?? string.Empty;
}
Console.WriteLine($"""
Summary:
{string.Join("\n", results)}
""");After inputting a bunch of content, use 000 to end the question and let AI summarize the user's words.
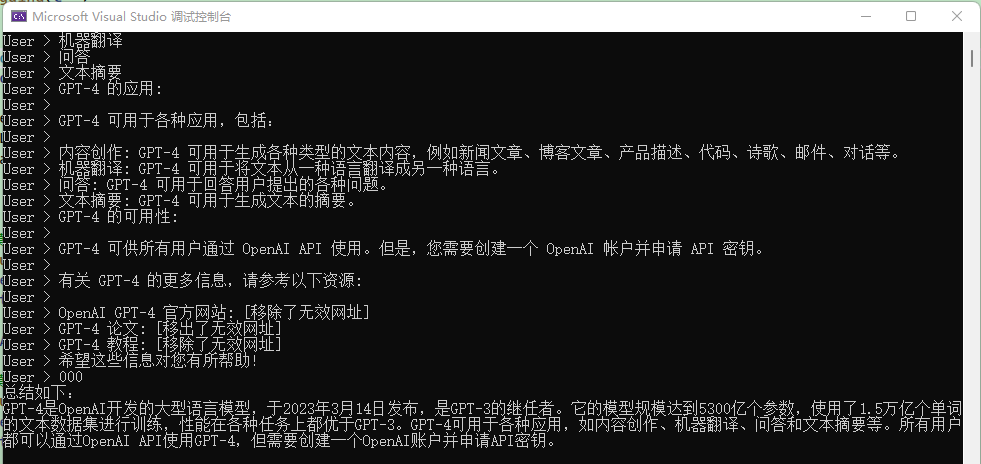
However, after debugging, it was found that the TextChunker's processing of this text seems to be inadequate because the text is recognized as only one line and one paragraph despite having many lines.
This may be related to the TextChunker separator, as SK is mainly oriented towards English.The demonstration effect in this section is not good, but the main purpose is to let users know that KernelFunctionFactory.CreateFromPrompt can create prompt templates more conveniently, use PromptExecutionSettings to configure temperature, and use TextChunker to split text.
When configuring PromptExecutionSettings, three parameters appear, among which MaxTokens represents the maximum number of tokens for the robot's response, which can avoid the robot talking too much.
The functions of the other two parameters are:
Temperature: The value ranges from 0 to 2. Simply put, the smaller the value of the temperature parameter, the more certain the model will return a result. The larger the value, the stronger the AI's imagination and the more likely it is to deviate from reality. Generally, for poetry, science fiction, and other genres, a larger value can be set to allow the AI to make more imaginative responses.
TopP: Another method different from Temperature, called nucleus sampling, where the model considers the results with tokens of the TopP probability mass. Therefore, 0.1 means that the results only consider the tokens that make up the top 10% of the probability mass.
It is generally recommended to change one of the parameters, not both.
For more related parameter configurations, please refer to https://learn.microsoft.com/en-us/azure/ai-services/openai/reference.
Configure Prompt Words
A new usage of creating a function was mentioned earlier:
var func = KernelFunctionFactory.CreateFromPrompt(
SummarizeConversationDefinition, // Prompt word
description: "Offer a summary of the conversation given a transcript.", // Description
executionSettings: promptExecutionSettings); // ConfigurationWhen creating prompt templates, you can use the PromptTemplateConfig type to adjust the parameters that control the behavior of prompts.
// Maximum token for the summary content
const int MaxTokens = 1024;
// Prompt template
const string SummarizeConversationDefinition = "...";
var func = kernel.CreateFunctionFromPrompt(new PromptTemplateConfig
{
// Name does not support Chinese and special characters
Name = "chat",
Description = "Offer a summary of the conversation given a transcript.",
Template = SummarizeConversationDefinition,
TemplateFormat = "semantic-kernel",
InputVariables = new List<InputVariable>
{
new InputVariable{Name = "request", Description = "User's question", IsRequired = true }
},
ExecutionSettings = new Dictionary<string, PromptExecutionSettings>
{
{
"default",
new OpenAIPromptExecutionSettings(){
MaxTokens = MaxTokens,
Temperature = 0
}
},
}
});
The configuration in the ExecutionSettings section is effective for the models used, and not all configurations here will take effect at the same time, but will take effect according to the actual model used.
ExecutionSettings = new Dictionary<string, PromptExecutionSettings>
{
{
"default",
new OpenAIPromptExecutionSettings()
{
MaxTokens = 1000,
Temperature = 0
}
},
{
"gpt-3.5-turbo", new OpenAIPromptExecutionSettings()
{
ModelId = "gpt-3.5-turbo-0613",
MaxTokens = 4000,
Temperature = 0.2
}
},
{
"gpt-4",
new OpenAIPromptExecutionSettings()
{
ModelId = "gpt-4-1106-preview",
MaxTokens = 8000,
Temperature = 0.3
}
}
}Talking about this, let me reiterate that using a file to configure prompt templates is similar to using code.
We can also store configurations consistent with the code in a file, and the directory file structure is as follows:
└─── chat
│
└─── config.json
└─── skprompt.txtThe template file consists of config.json and skprompt.txt. skprompt.txt configures prompt words, consistent with the Template field of PromptTemplateConfig.
The content involved in config.json is relatively extensive. You can compare the json below with the code in the implementation summary section, and the two are almost identical.
{
"schema": 1,
"type": "completion",
"description": "Summarize this part of the conversation based on a dialogue record.",
"execution_settings": {
"default": {
"max_tokens": 1000,
"temperature": 0
},
"gpt-3.5-turbo": {
"model_id": "gpt-3.5-turbo-0613",
"max_tokens": 4000,
"temperature": 0.1
},
"gpt-4": {
"model_id": "gpt-4-1106-preview",
"max_tokens": 8000,
"temperature": 0.3
}
},
"input_variables": [
{
"name": "request",
"description": "User's question.",```json
{
"variables": [
{
"name": "request",
"description": "用户的问题.",
"required": true
},
{
"name": "history",
"description": "用户的问题.",
"required": true
}
]
}C# code:
// Name does not support Chinese and special characters
Name = "chat",
Description = "Provide a summary of the conversation.",
Template = SummarizeConversationDefinition,
TemplateFormat = "semantic-kernel",
InputVariables = new List<InputVariable>
{
new InputVariable{Name = "request", Description = "User's question.", IsRequired = true }
},
ExecutionSettings = new Dictionary<string, PromptExecutionSettings>
{
{
"default",
new OpenAIPromptExecutionSettings()
{
MaxTokens = 1000,
Temperature = 0
}
},
{
"gpt-3.5-turbo", new OpenAIPromptExecutionSettings()
{
ModelId = "gpt-3.5-turbo-0613",
MaxTokens = 4000,
Temperature = 0.2
}
},
{
"gpt-4",
new OpenAIPromptExecutionSettings()
{
ModelId = "gpt-4-1106-preview",
MaxTokens = 8000,
Temperature = 0.3
}
}
}Prompt template syntax
At the moment, we have used prompt template syntax in two places, which are variables and function calls. As the usage has been covered before, there's no need to repeat that here.
Variables
The usage of variables is straightforward. Use {$variable name} in the prompt project to indicate a variable, such as {$name}.
Then in the conversation, there are various ways to insert values, such as using KernelArguments to store variable values:
new KernelArguments
{
{ "name", "Goliang" }
});Function calls
The prompt template can also explicitly call a function, which was mentioned in the Implementation Summary section. For example, defining a function like this:
// Without <code>Kernel kernel</code>
[KernelFunction, Description("Provide a summary of a long conversation.")]
public async Task<string> SummarizeConversationAsync(
[Description("Long conversation.")] string input)
{
await Task.CompletedTask;
return input;
}
// With <code>Kernel kernel</code>
``````csharp
[KernelFunction, Description("Summarizes a long conversation record.")]
public async Task<string> SummarizeConversationAsync(
[Description("A long conversation record.")] string input, Kernel kernel)
{
await Task.CompletedTask;
return input;
}
[KernelFunction]
[Description("Sends an email to a recipient.")]
public async Task SendEmailAsync(
Kernel kernel,
string recipientEmails,
string subject,
string body
)
{
// Add logic to send an email using the recipientEmails, subject, and body
// For now, we'll just print out a success message to the console
Console.WriteLine("Email sent!");
}
```
The usage example of text generation is as follows, let AI summarize the text:

Following this example, we first write extension functions in Env.cs to configure text generation using <code>.AddAzureOpenAITextGeneration()</code> instead of chat dialogue.
```csharp
public static IKernelBuilder WithAzureOpenAIText(this IKernelBuilder builder)
{
var configuration = GetConfiguration();
// Need to switch to a different model, such as gpt-35-turbo-instruct
var AzureOpenAIDeploymentName = "ca";
var AzureOpenAIModelId = "gpt-35-turbo-instruct";
var AzureOpenAIEndpoint = configuration["AzureOpenAI:Endpoint"]!;
var AzureOpenAIApiKey = configuration["AzureOpenAI:ApiKey"]!;
builder.Services.AddLogging(c =>
{
c.AddDebug()
.SetMinimumLevel(LogLevel.Trace)
.AddSimpleConsole(options =>
{
options.IncludeScopes = true;
options.SingleLine = true;
options.TimestampFormat = "yyyy-MM-dd HH:mm:ss ";
});
});
// Use Chat, which is a large language model chat
builder.Services.AddAzureOpenAITextGeneration(
AzureOpenAIDeploymentName,
AzureOpenAIEndpoint,
AzureOpenAIApiKey,
modelId: AzureOpenAIModelId
);
return builder;
}Then write the question code, and the user can input text in multiple lines. Finally, use 000 to end the input and submit the text to AI for summarization. To avoid AI talking too much, ExecutionSettings are used to configure related parameters.
The code example is as follows:
builder = builder.WithAzureOpenAIText();
var kernel = builder.Build();
Console.WriteLine("Input text:");
var request = "";
while (true)
{
var input = Console.ReadLine();
if (input == "000")
{
break;
}
request += Environment.NewLine;
request += input;
}```csharp
var func = kernel.CreateFunctionFromPrompt(new PromptTemplateConfig
{
Name = "chat",
Description = "Give a summary of a conversation record.",
// User text
Template = request,
TemplateFormat = "semantic-kernel",
ExecutionSettings = new Dictionary<string, PromptExecutionSettings>
{
{
"default",
new OpenAIPromptExecutionSettings()
{
MaxTokens = 100,
Temperature = (float)0.3,
TopP = (float)1,
FrequencyPenalty = (float)0,
PresencePenalty = (float)0
}
}
}
});
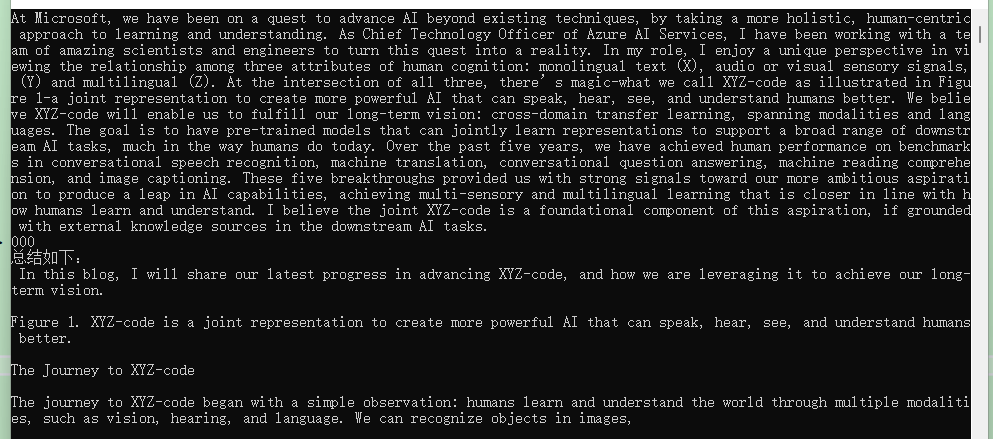
var result = await func.InvokeAsync(kernel);
Console.WriteLine($"""
Summary:
{string.Join("\n", result)}
""");
Semantic Kernel Plugins
Semantic Kernel provides plugins in the packages starting with Microsoft.SemanticKernel.Plugins. Different packages contain plugins with different functionalities. Most of them are still in development, so this section provides only a brief explanation.
Currently, the following packages in the official repository provide some plugins:
├─Plugins.Core
├─Plugins.Document
├─Plugins.Memory
├─Plugins.MsGraph
└─Plugins.WebWhen searching for NuGet packages, the
Microsoft.SemanticKernel.prefix needs to be added.
Additionally, Semantic Kernel also allows using plugins through remote swagger.json. For more details, please refer to the documentation: https://learn.microsoft.com/en-us/semantic-kernel/agents/plugins/openai-plugins
The Plugins.Core contains the most basic and simple plugins:
// Read from and write to files
FileIOPlugin
// HTTP request and return string result
HttpPlugin
// Provides only + and - operations
MathPlugin
// Simple text operations such as case changes
TextPlugin
// Gets the local date and time
TimePlugin
// Waits for a period of time before performing an operation
WaitPluginSince these plugins are not very helpful for this demonstration and have very simple functionalities, they will not be covered here. The following section provides a brief explanation of the document plugins.
Document Plugins
Install Microsoft.SemanticKernel.Plugins.Document (the preview version must be selected), which contains the document plugins. These plugins use the DocumentFormat.OpenXml project, which supports the following document formats:> DocumentFormat.OpenXml project address: https://github.com/dotnet/Open-XML-SDK
- WordprocessingML: Used for creating and editing Word documents (.docx)
- SpreadsheetML: Used for creating and editing Excel spreadsheets (.xlsx)
- PowerPointML: Used for creating and editing PowerPoint presentations (.pptx)
- VisioML: Used for creating and editing Visio diagrams (.vsdx)
- ProjectML: Used for creating and editing Project files (.mpp)
- DiagramML: Used for creating and editing Visio diagrams (.vsdx)
- PublisherML: Used for creating and editing Publisher publications (.pubx)
- InfoPathML: Used for creating and editing InfoPath forms (.xsn)
The document plugins currently do not have practical applications, but loading documents to extract text is convenient. The code example is as follows:
DocumentPlugin documentPlugin = new (new WordDocumentConnector(), new LocalFileSystemConnector());
string filePath = "(Full Version) Basic Financial Knowledge.docx";
string text = await documentPlugin.ReadTextAsync(filePath);
Console.WriteLine(text);As these plugins are currently unfinished, no further explanation will be provided here.
planners
Still a work in progress, and no further details will be provided here.
Because I also haven't figured out how to use this thing.
Kernel Memory: Building a Document Knowledge Base
Kernel Memory is a personal project of a foreigner, supporting PDF and Word documents, PowerPoint presentations, images, spreadsheets, and more. It extracts information and generates records by utilizing a large language model (LLM), embedding, and vector storage. Its primary purpose is to provide interfaces for document processing, with the most commonly used scenario being knowledge base systems. If feasible, it is recommended to deploy a Fastgpt system for research.
However, Kernel Memory is still a work in progress, and its documentation is also incomplete. Therefore, the upcoming section will only cover the most essential parts. Interested readers are advised to directly review the source code.
Kernel Memory project documentation: https://microsoft.github.io/kernel-memory/
Kernel Memory project repository: https://github.com/microsoft/kernel-memory
Open the Kernel Memory project repository and pull the project to your local machine.
To explain the knowledge base system, you can understand it in this way. Everyone knows that training a medical model is very troublesome, not to mention whether the machine's GPU is powerful enough. Just training AI alone requires mastering various professional knowledge. If a new requirement arises, it may be necessary to retrain a model, which is very inconvenient.
Therefore, there is the presence of large language models, which are characterized by learning everything but not being specialized or deep enough. The benefit is that it can be used for anything, whether it's medicine, photography, and so on.
Although it lacks expertise in some areas, we address part of the issue with this workaround.First, extract the text from docx, pdf, and other formats, then split it into multiple paragraphs, and use an AI model to generate relevant vectors for each paragraph. The author does not understand the principle of this vector, but it can be simply understood as word segmentation. After generating the vectors, store both the paragraph texts and vectors in the database (which needs to support vectors).

When a user asks "what is a report", search in the database first based on vectors to determine the similarity, retrieve several relevant paragraphs, and send these paragraphs and the user's question to the AI together. Compared to inserting some background knowledge in the prompt template and adding the user's question for AI to summarize and answer.
The author suggests that if conditions permit, deploy an open-source version of the Fastgpt system, study this system, and then explore Kernel Memory. You will find it very simple. Similarly, if conditions permit, deploy a LobeHub, an open-source AI conversation system, study how to use it, and then delve into the Semantic Kernel document, and then the source code.
Handling web pages
Kernel Memory supports importing information from web pages in three ways: web scraping, importing documents, and directly providing strings. Since Kernel Memory provides a Service example with some worth-studying code, below is an example of starting this Web service and then pushing the document to be processed by the Service in the client, which does not interact with AI itself.
Since this step is complicated, if readers are unable to do it, they can directly skip it, and later it will be explained how to write one.
Open the service/Service path in the kernel-memory source code.
Use the following command to start the service:
dotnet run setupThe purpose of this console is to help us generate relevant configurations. After starting this console, select the corresponding options as prompted (use the up and down arrow keys to select options, and press the enter key to confirm), and fill in the configuration content, which will be stored in appsettings.Development.json.
If readers do not understand how to use this console, they can directly replace the following JSON with appsettings.Development.json.
There are a few places that readers need to configure.
- AccessKey1 and AccessKey2 are validation keys required for the client to use this service, you can fill in random letters.
- AzureAIDocIntel, AzureOpenAIEmbedding, and AzureOpenAIText should be filled in according to actual circumstances.
{
"KernelMemory": {
"Service": {
"RunWebService": true,
"RunHandlers": true,
"OpenApiEnabled": true,
"Handlers": {}
},
"ContentStorageType": "SimpleFileStorage",{
"TextGeneratorType": "AzureOpenAIText",
"ServiceAuthorization": {
"Enabled": true,
"AuthenticationType": "APIKey",
"HttpHeaderName": "Authorization",
"AccessKey1": "CustomKey1",
"AccessKey2": "CustomKey2"
},
"DataIngestion": {
"OrchestrationType": "Distributed",
"DistributedOrchestration": {
"QueueType": "SimpleQueues"
},
"EmbeddingGenerationEnabled": true,
"EmbeddingGeneratorTypes": [
"AzureOpenAIEmbedding"
],
"MemoryDbTypes": [
"SimpleVectorDb"
],
"ImageOcrType": "AzureAIDocIntel",
"TextPartitioning": {
"MaxTokensPerParagraph": 1000,
"MaxTokensPerLine": 300,
"OverlappingTokens": 100
},
"DefaultSteps": []
},
"Retrieval": {
"MemoryDbType": "SimpleVectorDb",
"EmbeddingGeneratorType": "AzureOpenAIEmbedding",
"SearchClient": {
"MaxAskPromptSize": -1,
"MaxMatchesCount": 100,
"AnswerTokens": 300,
"EmptyAnswer": "INFO NOT FOUND"
}
},
"Services": {
"SimpleQueues": {
"Directory": "_tmp_queues"
},
"SimpleFileStorage": {
"Directory": "_tmp_files"
},
"AzureAIDocIntel": {
"Auth": "ApiKey",
"Endpoint": "https://aaa.openai.azure.com/",
"APIKey": "aaa"
},
"AzureOpenAIEmbedding": {
"APIType": "EmbeddingGeneration",
"Auth": "ApiKey",
"Endpoint": "https://aaa.openai.azure.com/",
"Deployment": "aitext",
"APIKey": "aaa"
},
"SimpleVectorDb": {
...
}
}
}```json
{
"KernelMemory": {
"Storage": {
"Type": "FileSystem",
"Settings": {
"Directory": "_tmp_vectors"
}
},
"AzureOpenAIText": {
"APIType": "ChatCompletion",
"Auth": "ApiKey",
"Endpoint": "https://aaa.openai.azure.com/",
"Deployment": "myai",
"APIKey": "aaa",
"MaxRetries": 10
}
},
"Logging": {
"LogLevel": {
"Default": "Warning"
}
},
"AllowedHosts": "*"
}
```using Microsoft.SemanticKernel.Connectors.OpenAI;
var memory = new KernelMemoryBuilder()
// Location of vector storage after document parsing, can choose Postgres, etc.,
// Choose to store vectors in local temporary files here
.WithSimpleVectorDb(new SimpleVectorDbConfig
{
Directory = "aaa"
})
// Configure document parsing vector model
.WithAzureOpenAITextEmbeddingGeneration(new AzureOpenAIConfig
{
Deployment = "aitext",
Endpoint = "https://aaa.openai.azure.com/",
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIType = AzureOpenAIConfig.APITypes.EmbeddingGeneration,
APIKey = "aaa"
})
// Configure text generation model
.WithAzureOpenAITextGeneration(new AzureOpenAIConfig
{
Deployment = "myai",
Endpoint = "https://aaa.openai.azure.com/",
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIKey = "aaa",
APIType = AzureOpenAIConfig.APITypes.ChatCompletion
})
.Build();
// Import webpage
await memory.ImportWebPageAsync(
"https://baike.baidu.com/item/比特币挖矿机/12536531",
documentId: "doc02");
// Wait for ingestion to complete, usually 1-2 seconds
Console.WriteLine("Processing document, please wait...");
while (!await memory.IsDocumentReadyAsync(documentId: "doc02"))
{
await Task.Delay(TimeSpan.FromMilliseconds(1500));
}
// Ask a question
var answer = await memory.AskAsync("比特币是什么?");
Console.WriteLine($"\nAnswer: {answer.Result}");
First use KernelMemoryBuilder to build the configuration. There are multiple configurations, and two models will be used, one is the vector model, and the other is the text generation model (can use a conversational model, such as gpt-4-32k).
Next, explain the relevant knowledge of each step in the workflow of the program.
First, explain where the file will be stored after importing the file, i.e., where the file will be stored after importing the file. The interface for storing files is IContentStorage, and there are currently two implementations:
AzureBlobsStorage
// Store to directory
SimpleFileStorageUsage:The Kernel Memory does not yet support MongoDB, but you can implement your own using the IContentStorage interface.
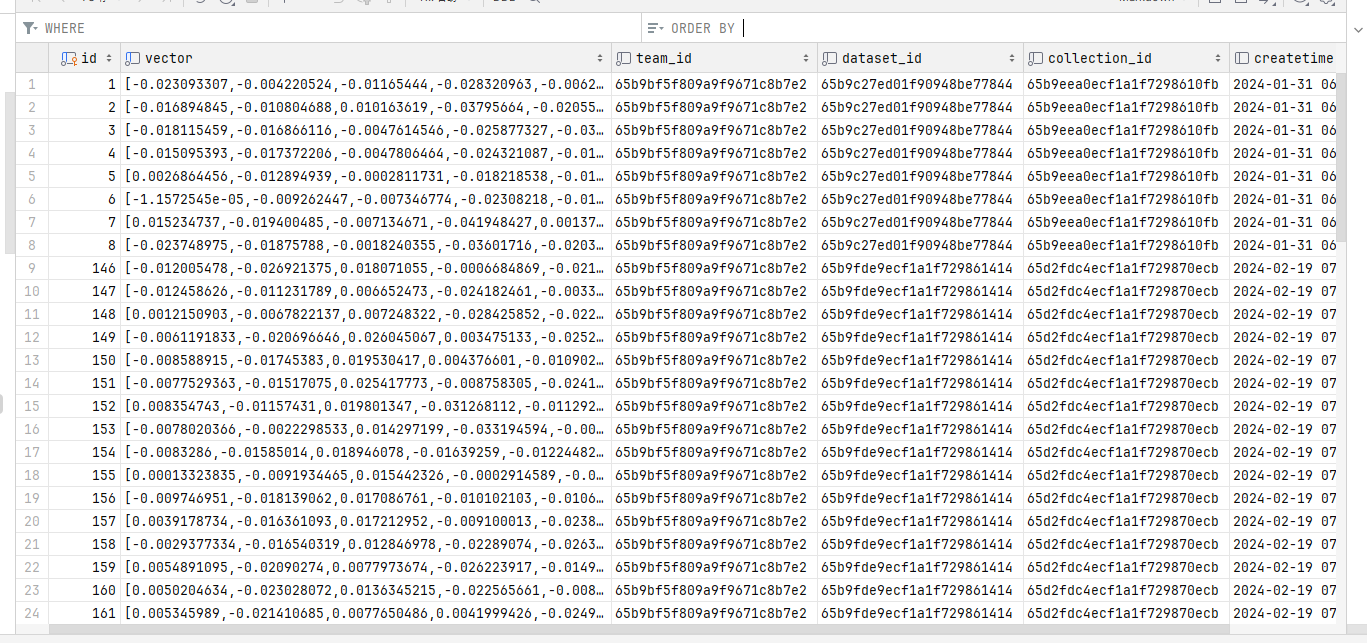
After parsing the document locally, it will be segmented, as shown in the q column on the right.

Next, configure the document to generate vector models. Import the file document and extract the text locally. An AI model is needed to generate vectors from the text.
The parsed vectors look like this:
To generate vectors from text, you need to use the ITextEmbeddingGenerator interface, currently with two implementations:
AzureOpenAITextEmbeddingGenerator
OpenAITextEmbeddingGeneratorExample:
var memory = new KernelMemoryBuilder()
// Configure the document parsing vector model
.WithAzureOpenAITextEmbeddingGeneration(new AzureOpenAIConfig
{
Deployment = "aitext",
Endpoint = "https://xxx.openai.azure.com/",
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIType = AzureOpenAIConfig.APITypes.EmbeddingGeneration,
APIKey = "xxx"
})
.WithOpenAITextEmbeddingGeneration(new OpenAIConfig
{
... ...
})After generating vectors, you need to store these vectors and implement the IMemoryDb interface. The following configurations are available:
// Location to store parsed document vectors, can choose Postgres, etc.,
// Here, using local temporary file storage for vectors
.WithSimpleVectorDb(new SimpleVectorDbConfig
{
Directory = "aaa"
})
.WithAzureAISearchMemoryDb(new AzureAISearchConfig
{
})
.WithPostgresMemoryDb(new PostgresConfig
{
})
.WithQdrantMemoryDb(new QdrantConfig
{
})
.WithRedisMemoryDb("host=....")When a user asks a question, relevant methods in this IMemoryDb will be called to search for vectors and indices in the document and find related text.After finding the relevant text, it needs to be sent to AI for processing using the ITextGenerator interface, which currently has two implementations:
AzureOpenAITextGenerator
OpenAITextGeneratorConfiguration example:
// Configure text generation model
.WithAzureOpenAITextGeneration(new AzureOpenAIConfig
{
Deployment = "myai",
Endpoint = "https://aaa.openai.azure.com/",
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIKey = "aaa",
APIType = AzureOpenAIConfig.APITypes.ChatCompletion
})When importing documents, first extract the text from the document and then segment it.
Parse the vector for each segment of text using a vector model and store it in a service provided by the IMemoryDb interface, such as a Postgres database.
When asking questions or searching for content, search for vectors from the location of IMemoryDb, retrieve relevant text, send it to AI (using text generation model) relative to the prompts, and let AI learn from these prompts to answer user questions.
For detailed source code, refer to Microsoft.KernelMemory.Search.SearchClient. Due to the extensive source code, it will not be elaborated here.

Saying this may not be easy for everyone to understand, so let's demonstrate with the following code.
// Import the document
await memory.ImportDocumentAsync(
"aaa/(Full version) Basic Financial Knowledge.docx",
documentId: "doc02");
Console.WriteLine("Processing the document, please wait...");
while (!await memory.IsDocumentReadyAsync(documentId: "doc02"))
{
await Task.Delay(TimeSpan.FromMilliseconds(1500));
}
var answer1 = await memory.SearchAsync("How to make a report?");
// Each Citation represents a document file
foreach (Citation citation in answer1.Results)
{
// Text related to the search keyword
foreach(var partition in citation.Partitions)
{
Console.WriteLine(partition.Text);
}
}
var answer2 = await memory.AskAsync("How to make a report?");
Console.WriteLine($"\nAnswer: {answer2.Result}");Readers can set a breakpoint inside the foreach loop to view the relevant documents when the user asks "How to make a report?" and then refer to Fastgpt's search configuration to build a knowledge base system like this.

文章评论