初始化
KernelMemory 启动时,会检查配置,即使当前代码没有使用到相关功能。
var hasQueueFactory = (this._memoryServiceCollection.HasService<QueueClientFactory>());
var hasContentStorage = (this._memoryServiceCollection.HasService<IContentStorage>());
var hasMimeDetector = (this._memoryServiceCollection.HasService<IMimeTypeDetection>());
var hasEmbeddingGenerator = (this._memoryServiceCollection.HasService<ITextEmbeddingGenerator>());
var hasMemoryDb = (this._memoryServiceCollection.HasService<IMemoryDb>());
var hasTextGenerator = (this._memoryServiceCollection.HasService<ITextGenerator>());
if (hasContentStorage && hasMimeDetector && hasEmbeddingGenerator && hasMemoryDb && hasTextGenerator)
{
return hasQueueFactory ? ClientTypes.AsyncService : ClientTypes.SyncServerless;
}由于 KernelMemory 本身有默认服务,因此只有 ITextEmbeddingGenerator、ITextGenerator 两个一定要配置。
var memory = new KernelMemoryBuilder()
// 配置文档解析向量模型
.WithAzureOpenAITextEmbeddingGeneration(new AzureOpenAIConfig
{
Deployment = "aaa",
Endpoint = Environment.GetEnvironmentVariable("AzureOpenAI:Endpoint"),
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIType = AzureOpenAIConfig.APITypes.EmbeddingGeneration,
APIKey = Environment.GetEnvironmentVariable("AzureOpenAI:ApiKey")
})
// 配置文本生成模型
.WithAzureOpenAITextGeneration(new AzureOpenAIConfig
{
Deployment = "aaa",
Endpoint = Environment.GetEnvironmentVariable("AzureOpenAI:Endpoint"),
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIKey = Environment.GetEnvironmentVariable("AzureOpenAI:ApiKey"),
APIType = AzureOpenAIConfig.APITypes.ChatCompletion
})导入文档
如果只是导入文档、生成向量,则只会使用到 Embedding 模型。
var memory = new KernelMemoryBuilder()
// 存储文件
.WithSimpleFileStorage("files")
// 配置文档解析向量模型
.WithAzureOpenAITextEmbeddingGeneration(new AzureOpenAIConfig
{
Deployment = "aaa",
Endpoint = Environment.GetEnvironmentVariable("AzureOpenAI:Endpoint"),
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIType = AzureOpenAIConfig.APITypes.EmbeddingGeneration,
APIKey = Environment.GetEnvironmentVariable("AzureOpenAI:ApiKey")
})
// 配置文本生成模型
.WithAzureOpenAITextGeneration(new AzureOpenAIConfig
{
Deployment = "aaa",
Endpoint = Environment.GetEnvironmentVariable("AzureOpenAI:Endpoint"),
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
// 这里可以随便填,因为用不到
APIKey = "11111111111",
APIType = AzureOpenAIConfig.APITypes.ChatCompletion
})
//// 存储向量
//.WithSimpleVectorDb(new SimpleVectorDbConfig
//{
// Directory = "aaa"
//})
.Build();
// 导入网页
await memory.ImportWebPageAsync(
"https://baike.baidu.com/item/比特币挖矿机/12536531",
documentId: "doc02").ConfigureAwait(false);
// Wait for ingestion to complete, usually 1-2 seconds
Console.WriteLine("正在处理文档,请稍等...");
while (!await memory.IsDocumentReadyAsync(documentId: "doc02").ConfigureAwait(false))
{
await Task.Delay(TimeSpan.FromMilliseconds(1500)).ConfigureAwait(false);
}导入文档之后,会切割文档,生成多个 .txt 文件。
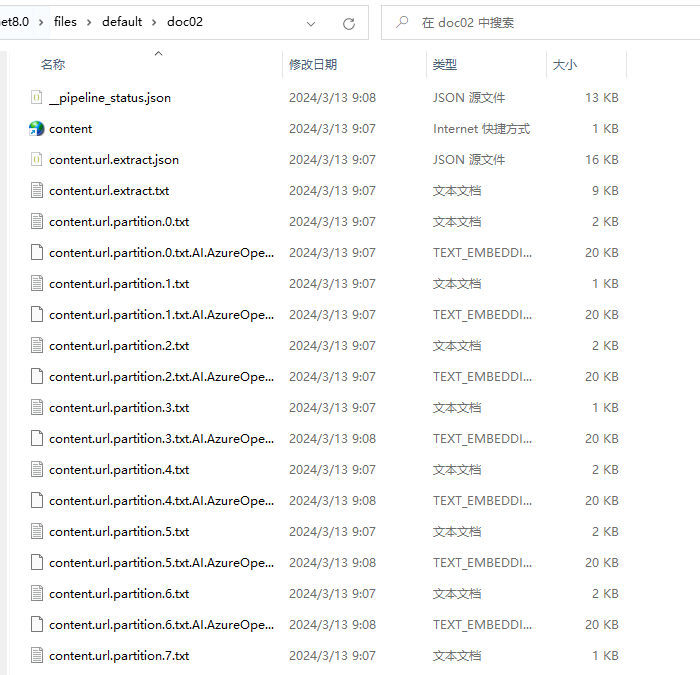
由于未配置向量存储位置,因此默认会在相同的命令下生成向量文件。比如 content.url.partition.0.txt.AI.AzureOpenAI.AzureOpenAITextEmbeddingGenerator.TODO.text_embedding。
每一个文档分片会生成一部分向量。
如果选择将文件存储到目录下,则会以 index}/{documentId 的方式存放,如果不设置 index,则默认使用 default。
await memory.ImportWebPageAsync(
"https://baike.baidu.com/item/比特币挖矿机/12536531",
documentId: "doc02",index: "test").ConfigureAwait(false);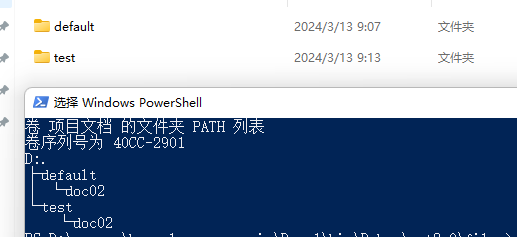
存储向量到数据库
默认情况下,向量是存储到存放文件的所在目录。
如果配置了 Memory ,则会指定存放到对应的位置,比如使用 Postgres 数据库存储向量。
// 存储向量
.WithPostgresMemoryDb(new PostgresConfig
{
ConnectionString = "Host=0.0.0.0;Port=5432;Username=postgres;Password=password;"
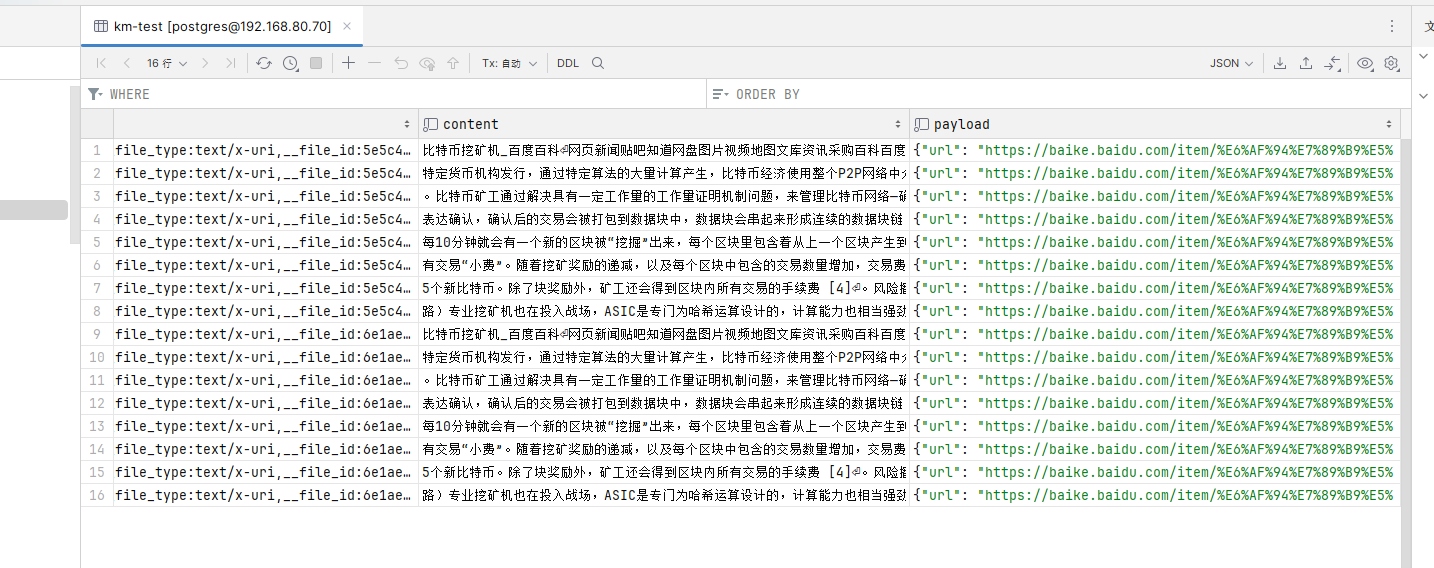
})默认情况下,会存储到 public 数据库的 km-test 表中。
主要是 embedding 和 content 两个字段。
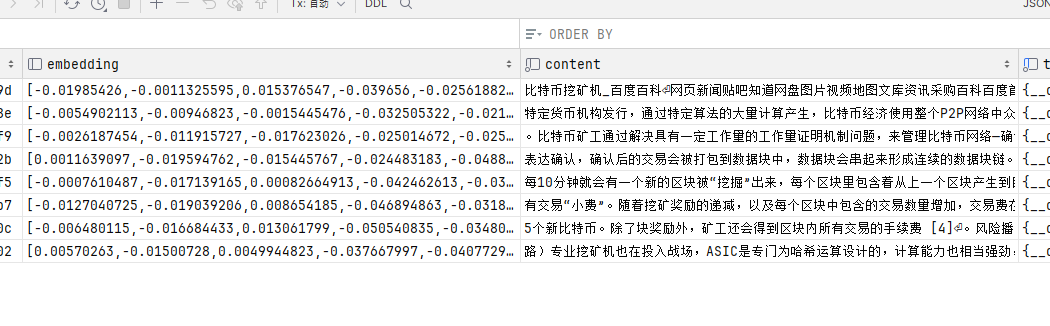
content 是切割文档后的每段文本,每段文本都会生成向量到 embedding 字段中。
全部代码示例如下:
var memory = new KernelMemoryBuilder()
// 存储文件
.WithSimpleFileStorage("files")
// 配置文档解析向量模型
.WithAzureOpenAITextEmbeddingGeneration(new AzureOpenAIConfig
{
//
})
// 存储向量
.WithPostgresMemoryDb(new PostgresConfig
{
ConnectionString = //
})
// 配置文本生成模型
.WithAzureOpenAITextGeneration(new AzureOpenAIConfig
{
//
})
.Build();
// 导入网页
await memory.ImportWebPageAsync(
"https://baike.baidu.com/item/比特币挖矿机/12536531",
documentId: "doc02",index: "test").ConfigureAwait(false);
// Wait for ingestion to complete, usually 1-2 seconds
Console.WriteLine("正在处理文档,请稍等...");
while (!await memory.IsDocumentReadyAsync(documentId: "doc02",index: "test")).ConfigureAwait(false))
{
await Task.Delay(TimeSpan.FromMilliseconds(1500)).ConfigureAwait(false);
}可以修改默认的数据库名称和表前缀:
// 存储向量
.WithPostgresMemoryDb(new PostgresConfig
{
ConnectionString = "Host=0.0.0.0;Port=5432;Username=postgres;Password=password;",
Schema = "数据库的名称",
TableNamePrefix = "km-"
})表不能直接设置名称,只能设置前缀,最终表的名称是 TableNamePrefix}{index。
所以,一般将知识库的 id 字符串动作 index,每个知识库一个表,每个知识库下有多个文件/文档。
如果我们使用数据库等存储向量,那么就没必要设置 Storage 了。
这个配置可以删除:
// 存储文件
.WithSimpleFileStorage("files")另外,框架应该没有做唯一检测,所以同一个文档,即 index、documentId 相同时,依然可以导入,但是这样做导致切割的文本会重复。
需要自行做好重复检测,避免重复导入同一个文档。
文档切割处理
当我们导入文档或导入网页地址时,框架会对文档进行一些比较复杂的处理。
// 导入网页
await memory.ImportWebPageAsync(
"https://baike.baidu.com/item/比特币挖矿机/12536531",
documentId: "doc02",index: "test").ConfigureAwait(false);ImportWebPageAsync 的定义如下:
public Task<string> ImportWebPageAsync(
string url,
string? documentId = null,
TagCollection? tags = null,
string? index = null,
IEnumerable<string>? steps = null,
CancellationToken cancellationToken = default);ImportWebPageAsync 中有个 steps 参数,是指示如何处理文档的。
默认自动设置四个步骤:

框架支持的所有步骤如下:
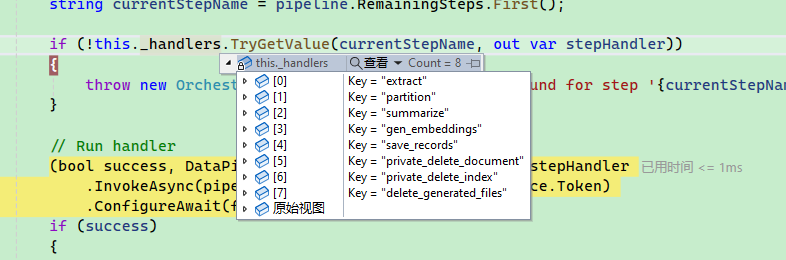
最后根据 steps 对文档进行多步处理,每一步对应一个 IPipelineStepHandler 类型。
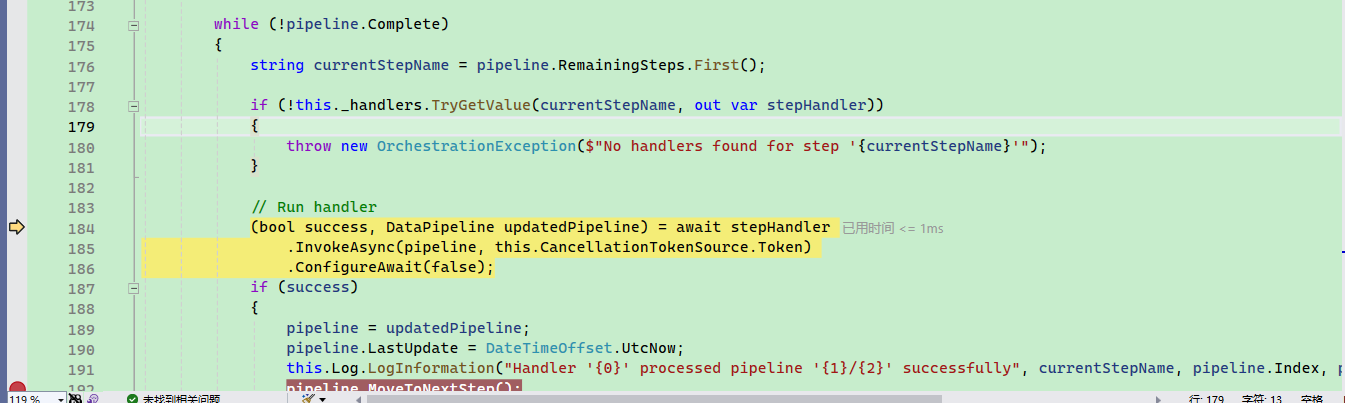

比如说 extract 内存摄取管道处理程序负责从文件中提取文本并将其保存到内容存储中。,就是切割文档分片的,其处理器是 TextExtractionHandler,可以对文本、Markdown、pdf、json、word、excel、html、图片等进行处理。TextPartitioningHandler 会将文本划为小块。
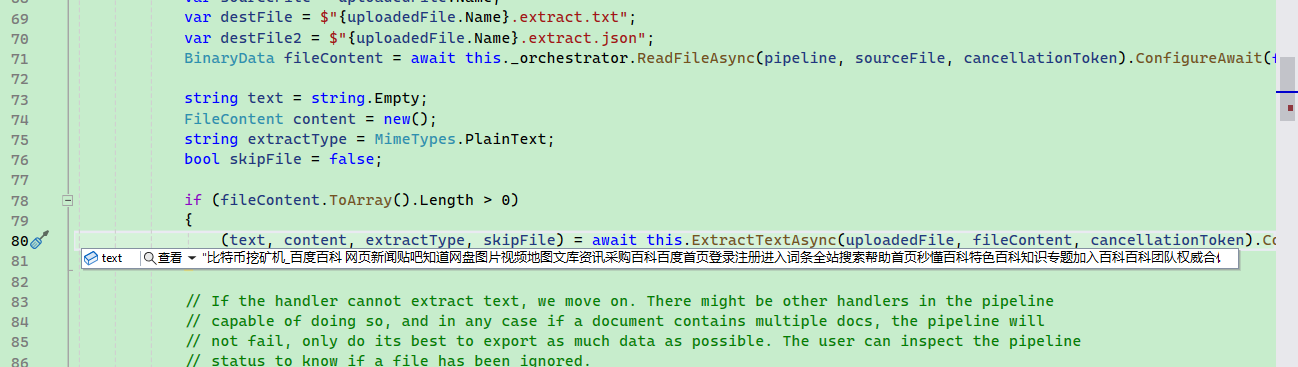
默认情况下,由框架注入这些处理器,代码在 service\Core\Handlers\DependencyInjection.cs 中。
/// <summary>
/// Register default handlers in the synchronous orchestrator (e.g. when not using queues)
/// </summary>
/// <param name="syncOrchestrator">Instance of <see cref="InProcessPipelineOrchestrator"/></param>
public static InProcessPipelineOrchestrator AddDefaultHandlers(this InProcessPipelineOrchestrator syncOrchestrator)
{
syncOrchestrator.AddHandler<TextExtractionHandler>(Constants.PipelineStepsExtract);
syncOrchestrator.AddHandler<TextPartitioningHandler>(Constants.PipelineStepsPartition);
syncOrchestrator.AddHandler<SummarizationHandler>(Constants.PipelineStepsSummarize);
syncOrchestrator.AddHandler<GenerateEmbeddingsHandler>(Constants.PipelineStepsGenEmbeddings);
syncOrchestrator.AddHandler<SaveRecordsHandler>(Constants.PipelineStepsSaveRecords);
syncOrchestrator.AddHandler<DeleteDocumentHandler>(Constants.PipelineStepsDeleteDocument);
syncOrchestrator.AddHandler<DeleteIndexHandler>(Constants.PipelineStepsDeleteIndex);
syncOrchestrator.AddHandler<DeleteGeneratedFilesHandler>(Constants.PipelineStepsDeleteGeneratedFiles);
return syncOrchestrator;
}
public static IServiceCollection AddHandlerAsHostedService<THandler>(
this IServiceCollection services, string stepName) where THandler : class, IPipelineStepHandler
{
services.AddTransient<THandler>(
serviceProvider => ActivatorUtilities.CreateInstance<THandler>(serviceProvider, stepName));
services.AddHostedService<HandlerAsAHostedService<THandler>>(
serviceProvider => ActivatorUtilities.CreateInstance<HandlerAsAHostedService<THandler>>(serviceProvider, stepName));
return services;
}
每个处理器都有自己的配置,比如通过 TextPartitioningOptions 配置 TextPartitioningHandler 切割文档的最大 token 数量。
不过 KernelMemory 框架不允许开发者直接操作这些执行器,如果需要配置相关处理器,则需要使用扩展函数,比如配置文档切片:
.WithCustomTextPartitioningOptions(new TextPartitioningOptions
{
// Max 99 tokens per sentence
MaxTokensPerLine = 99,
// When sentences are merged into paragraphs (aka partitions), stop at 299 tokens
MaxTokensPerParagraph = 299,
// Each paragraph contains the last 47 tokens from the previous one
OverlappingTokens = 47,
})
知识库搜索
通过知识库进行搜索提问,需要使用文本生成模型,当然聊模型也可以。
然后提问时,最好设置 index,前面说到,应该一个知识库一个 index,所以提问时,框架首先在对应的 index (对应一个表)中搜索关联的知识,然后将这些知识和问题推送到 AI 中,使用 AI 总结、回答。
var memory = new KernelMemoryBuilder()
// 配置文档解析向量模型
.WithAzureOpenAITextEmbeddingGeneration(new AzureOpenAIConfig
{
})
// 存储向量
.WithPostgresMemoryDb(new PostgresConfig
{
})
// 配置文本生成模型
.WithAzureOpenAITextGeneration(new AzureOpenAIConfig
{
})
.Build();
// Ask a question
var answer = await memory.AskAsync("比特币是什么?", index: "test").ConfigureAwait(false);
Console.WriteLine($"\nAnswer: {answer.Result}");在 SearchClient.AskAsync 方法中,可以找到这些搜索和提问的代码。
搜索:
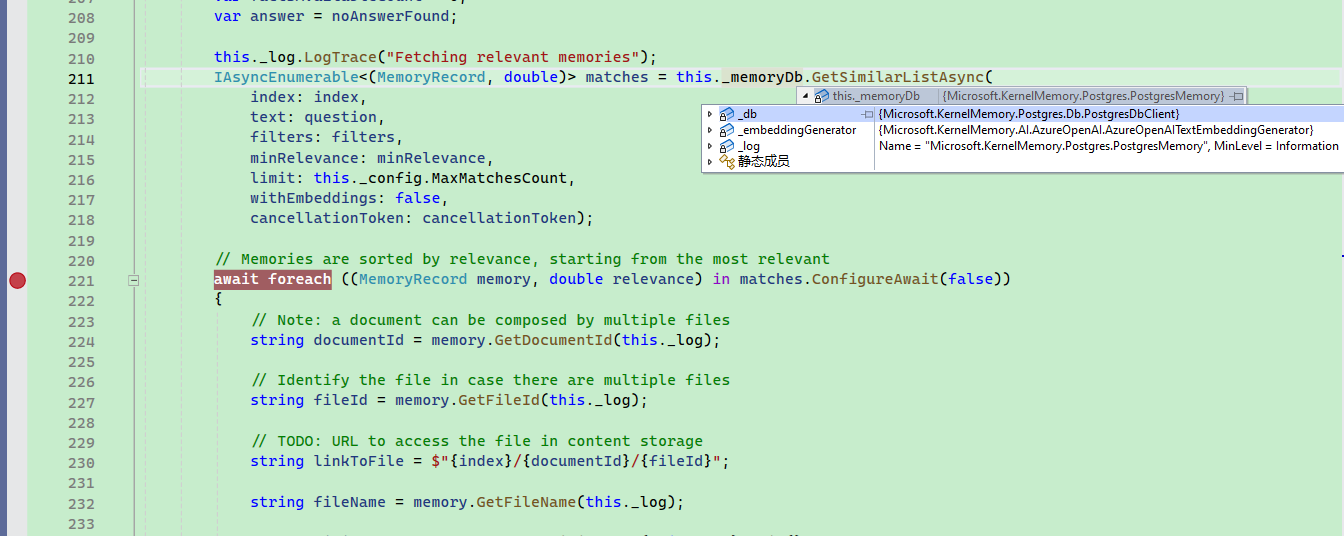
从向量数据库中搜索时,会给出多段相关的文本和相关度。
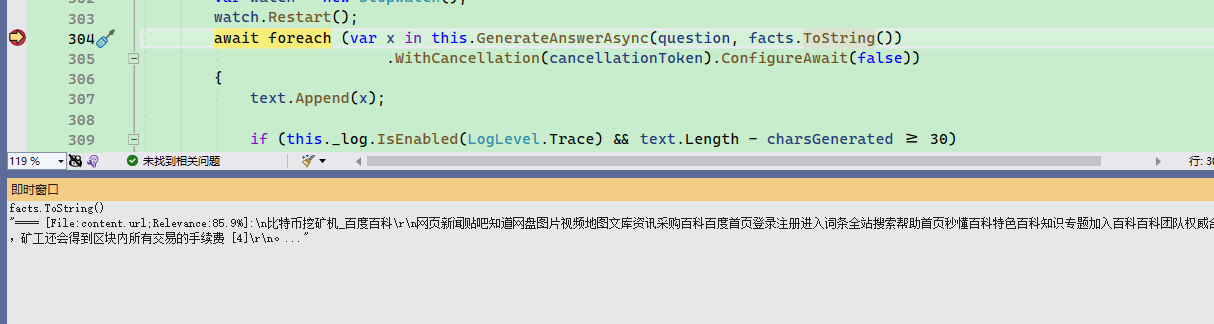
然后这些文本会被合并在一起,随着问题一起推送到 AI 中。
框架会将这些文本和问题生成提示工程。
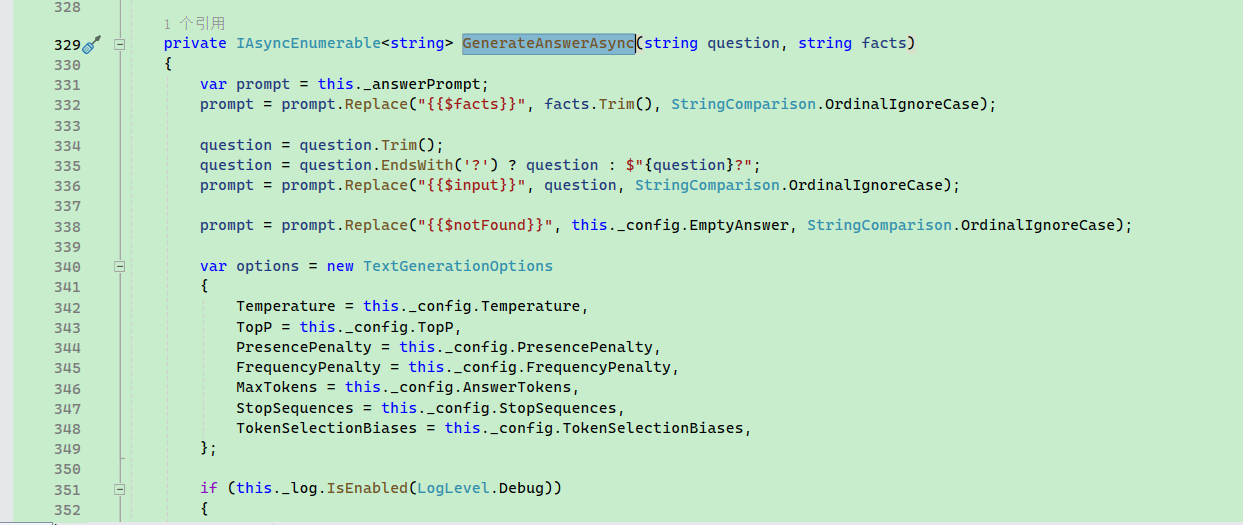
最后,var x in this.GenerateAnswerAsync(question, facts.ToString()) 以流式的方法返回文字。
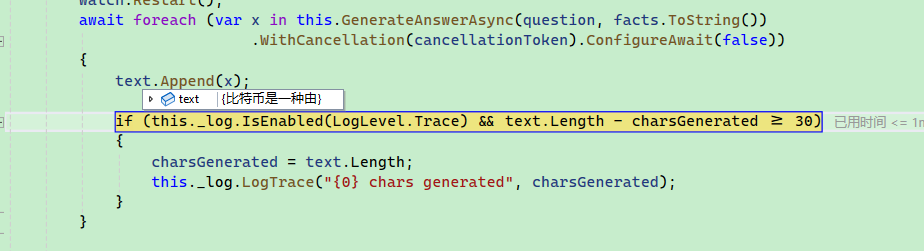

为了可以在搜索时使用配置,需要在构建服务时注入配置。
static async Task Main(string[] args)
{
var memoryBuilder = new KernelMemoryBuilder()
// ...
;
memoryBuilder.Services.AddSearchClientConfig(new SearchClientConfig
{
});
var memory = memoryBuilder.Build();搜索
可以使用 KernelMemory 对知识库进行搜索,但是不向 AI 提问。
示例如下:
var answer = await memory.SearchAsync("比特币是什么?", index: "test").ConfigureAwait(false);
Console.WriteLine($"\nAnswer: {answer.Results}");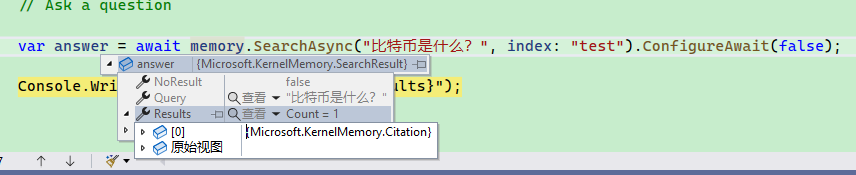
默认情况下,搜索时不会限制搜索到的文本数量,为了避免数量过大,可以设置 limit 参数,这样一来之后使用到相关性最强的几个文本。
var answer = await memory.SearchAsync("比特币是什么?", index: "test",limit:2).ConfigureAwait(false);完整定义如下:
/// <summary>
/// 在给定索引中搜索给定查询的相关文档列表.
/// </summary>
/// <param name="query">问题</param>
/// <param name="index">索引 index</param>
/// <param name="filter">过滤规则</param>
/// <param name="filters">要匹配的过滤器(使用包含或逻辑)。如果还提供了'filter',则该值将合并到此列表中。</param>
/// <param name="minRelevance">最小余弦相似度要求</param>
/// <param name="limit">返回结果的最大数目</param>
/// <param name="cancellationToken">异步任务取消令牌</returns>
public Task<SearchResult> SearchAsync(
string query,
string? index = null,
MemoryFilter? filter = null,
ICollection<MemoryFilter>? filters = null,
double minRelevance = 0,
int limit = -1,
CancellationToken cancellationToken = default);示例:
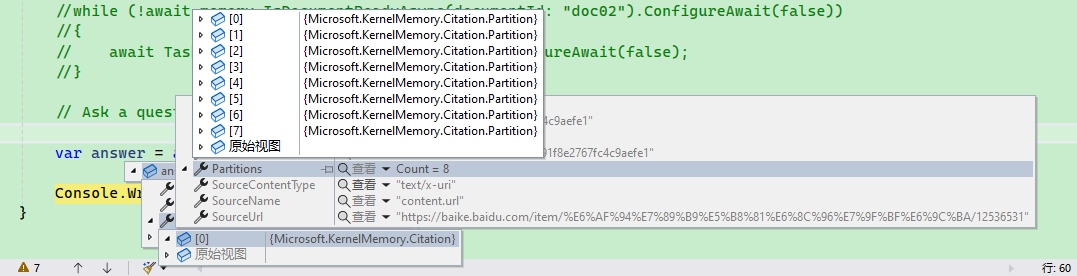
var searchResult = await memory.SearchAsync("比特币是什么?", index: "test", limit: 2).ConfigureAwait(false);
// 每个 Citation 表示一个文档文件
foreach (Citation citation in searchResult.Results)
{
// 与搜索关键词相关的文本
foreach (var partition in citation.Partitions)
{
Console.WriteLine(partition.Text);
}
}
修改 OpenAI 接口请求地址
默认情况下 OpenAI 接口只能请求 openai.com 地址,不能自定义 API 服务地址,很多时候需要自定义接入 oneapi 、ollama 等平台,因此需要修改请求地址。
定义 DelegatingHandler:
public class ADelegatingHandler : DelegatingHandler
{
public ADelegatingHandler(HttpMessageHandler innerHandler)
: base(innerHandler)
{
}
protected override async Task<HttpResponseMessage> SendAsync(HttpRequestMessage request, CancellationToken cancellationToken)
{
if (request.RequestUri.AbsoluteUri.StartsWith("https://api.openai.com/v1"))
request.RequestUri = new Uri(request.RequestUri.AbsoluteUri.Replace("https://api.openai.com/v1", "http://localhost:11434/api"));
var result = await base.SendAsync(request, cancellationToken);
return result;
}
protected override HttpResponseMessage Send(HttpRequestMessage request, CancellationToken cancellationToken)
{
if (request.RequestUri.AbsoluteUri.StartsWith("https://api.openai.com/v1"))
request.RequestUri = new Uri(request.RequestUri.AbsoluteUri.Replace("https://api.openai.com/v1", "http://localhost:11434/api"));
return base.Send(request, cancellationToken);
}
}构建 KernelMemory 时配置 HttpClient:
var memoryBuilder = new KernelMemoryBuilder()
// 文档解析后的向量存储位置,可以选择 Postgres 等,
// 这里选择使用本地临时文件存储向量
// 配置文档解析向量模型
.WithSimpleFileStorage(new SimpleFileStorageConfig
{
Directory = "aaaa"
})
.WithPostgresMemoryDb(new PostgresConfig
{
})
.WithOpenAITextEmbeddingGeneration(new OpenAIConfig
{
EmbeddingModel = "nomic-embed-text",
APIKey = "0"
}, httpClient: new HttpClient(new ADelegatingHandler(new HttpClientHandler())))
// 配置文本生成模型
.WithOpenAITextGeneration(new OpenAIConfig
{
TextModel = "gemma:7b",
APIKey = "0"
}, httpClient: new HttpClient(new ADelegatingHandler(new HttpClientHandler())));
文章评论