demo 仓库地址:https://github.com/whuanle/yolo8_demo
Ultralytics YOLOv8 是备受好评的实时目标检测和图像分割模型,主要功能是物体识别、分割图片物体、分类、姿态识别和跟踪等。Ultralytics 支持使用 CPU、GPU 进行训练,支持 x64、arm64 等 CPU 架构,支持苹果的 M1/M2 芯片,支持在边缘设备中训练和使用。
Ultralytics 对于个人免费,使用 【AGPL-3.0 许可】 开源协议,对于企业则需要付费。
Ultralytics 是框架的名称,YOLOv8 是该框架默认携带的模型的版本号,框架默认会自带多种用途模型,我们一般会选择在官方的模型上做训练。

Ultralytics YOLOv8 的物体识别功能很强大,如下图所示,能够准确识别图片中化了妆的妹子为 person(人类),甚至把床也识别出来了。

使用 Ultralytics,一般会经历以下过程:
- 训练(Train)模式:在自定义或预加载的数据集上微调您的模型。
- 验证(Val)模式:训练后进行校验,以验证模型性能。
- 预测(Predict)模式:在真实世界数据上释放模型的预测能力。
- 导出(Export)模式:以各种格式使模型准备就绪,部署至生产环境。
- 跟踪(Track)模式:将您的目标检测模型扩展到实时跟踪应用中。
- 基准(Benchmark)模式:在不同部署环境中分析模型的速度和准确性。
所以,本文也会按照该顺序,逐步讲解。
安装 Ultralytics
一般来说,直接使用 pip 安装即可。
# 从PyPI安装ultralytics包
pip install ultralytics官方文档的安装方式是最详细的,其它安装方式直接参考官方文档即可。
官方安装文档:https://docs.ultralytics.com/zh/quickstart/#ultralytics
安装 ultralytics 之后,在项目中使用 YOLO 名称引入 ultralytics:
from ultralytics import YOLOultralytics 默认是从运行目录中读写数据集、训练模型的,这样可能会比较乱。
可以在程序启动时,修改配置运行配置:
# 模型和训练模块,核心
from ultralytics import YOLO
# 设置模块
from ultralytics import settings
# 更新设置
settings.update({'runs_dir': './' , 'tensorboard': False})settings 也可以导出配置,或者从文件中加载配置:
def load(self):
"""Loads settings from the YAML file."""
super().update(yaml_load(self.file))
def save(self):
"""Saves the current settings to the YAML file."""
yaml_save(self.file, dict(self))
def update(self, *args, **kwargs):
"""Updates a setting value in the current settings."""
super().update(*args, **kwargs)
self.save()
def reset(self):
"""Resets the settings to default and saves them."""
self.clear()
self.update(self.defaults)
self.save()settings 可以设置的全部配置如下:
| 名称 | 示例值 | 数据类型 | 描述 |
|---|---|---|---|
settings_version |
'0.0.4' |
str |
Ultralytics settings 版本 |
datasets_dir |
'/path/to/datasets' |
str |
存储数据集的目录 |
weights_dir |
'/path/to/weights' |
str |
存储模型权重的目录 |
runs_dir |
'/path/to/runs' |
str |
存储实验运行的目录 |
uuid |
'a1b2c3d4' |
str |
当前设置的唯一标识符 |
sync |
True |
bool |
是否将分析和崩溃同步到HUB |
api_key |
'' |
str |
Ultralytics HUB API Key |
clearml |
True |
bool |
是否使用ClearML记录 |
comet |
True |
bool |
是否使用Comet ML进行实验跟踪和可视化 |
dvc |
True |
bool |
是否使用DVC进行实验跟踪和版本控制 |
hub |
True |
bool |
是否使用Ultralytics HUB集成 |
mlflow |
True |
bool |
是否使用MLFlow进行实验跟踪 |
neptune |
True |
bool |
是否使用Neptune进行实验跟踪 |
raytune |
True |
bool |
是否使用Ray Tune进行超参数调整 |
tensorboard |
True |
bool |
是否使用TensorBoard进行可视化 |
wandb |
True |
bool |
是否使用Weights & Biases记录 |
训练
ultralytics 中常见的文件格式有两种,模型以 .pt 结尾,模型或数据集以 .yaml 结尾。
可以基于官方模型进行训练,或者从已有模型进行训练,甚至在没有模型的情况下训练出自己的模型。
如果已经有模型,则无需再次训练。
官方文档的 demo 如下:
下面的代码不能直接启动。
from ultralytics import YOLO
# 加载一个模型
model = YOLO('yolov8n.yaml') # 从YAML建立一个新模型
model = YOLO('yolov8n.pt') # 加载预训练模型(推荐用于训练)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML建立并转移权重
# 训练模型
results = model.train(data='coco128.yaml', epochs=100, imgsz=640)官方的 yolov8n.pt 模型和 coco128.yaml 数据集,主要是人、动物、常见物体,可用于物体识别。
如果选择使用官方模型,则第一次使用时,会自动下载
yolov8n.pt到代码所在目录。
我们先来看看 .train() 训练模型时的参数。epochs 表示训练多少轮,一般 10 轮即可,100轮需要非常久的!imgsz 表示图片大小,当数据集的图片大小太大时,可以适当降低像素,官方的数据集图片大小是 640*480 ,已经提前处理好大小了。
coco128.yaml 是官方提供的数据集合,有 128 张图片,在程序首次运行时,会自动从官方仓库中拉取数据集存储到 datasets/coco128 下面,其中里面包含了一些图片和标注。当然,我们也可以从开源社区中获取更多的数据集,以及自己制作数据集,用来训练模型。
然后再回到加载模型这里。
我们通过官方配置文件,从零训练出一个模型:
from ultralytics import YOLO
# 加载一个模型
model = YOLO('yolov8n.yaml') # 从YAML建立一个新模型
# 训练模型
results = model.train(data='coco128.yaml', epochs=10, imgsz=640)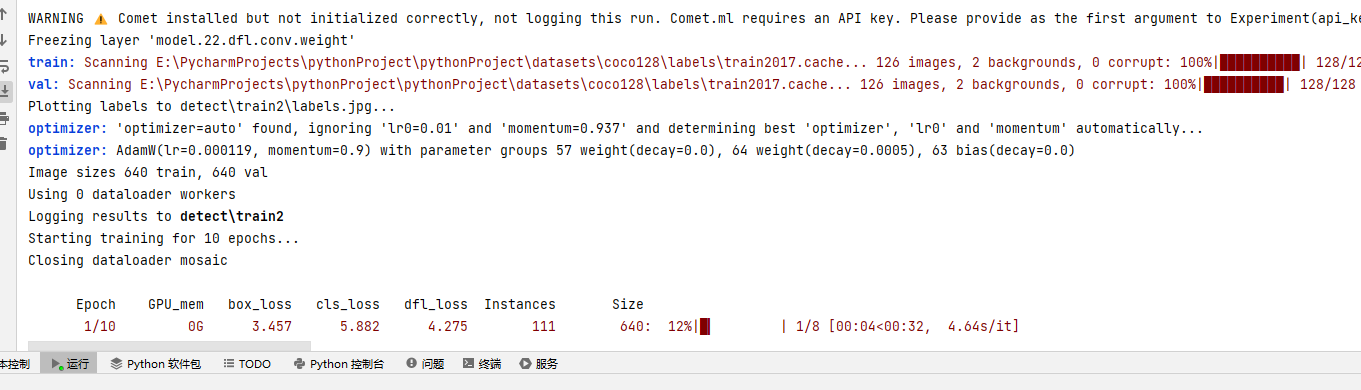
由于笔者只有 AMD 5600G,是集成显卡,因此跑起来特别慢。
如果你有指定的多个,可以在训练时指定:
results = model.train(data='coco128.yaml', epochs=10, imgsz=640, device=0)如果不指定,框架会自动选择 GPU。
可能笔者是 AMD 的 CPU,也有可能是因为不支持集成显卡,所以笔者是使用 CPU 训练的,超级慢。
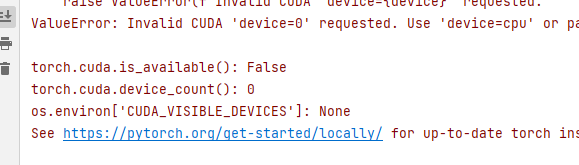
训练出的模型会存储在 detect 目录下。其它两种方式训练的模型也是如此,都会在 detect 目录下。
我们也可以导入已有的模型:
# 加载官方预训练模型
# model = YOLO('yolov8n.pt')
# 训练过的模型
model = YOLO('detect/train/weights/best.pt') 在使用 .train() 训练模型时,可以传递很多参数,全部参数说明如下:
| 键 | 值 | 描述 |
|---|---|---|
model |
None |
模型文件路径,例如 yolov8n.pt, yolov8n.yaml |
data |
None |
数据文件路径,例如 coco128.yaml |
epochs |
100 |
训练的轮次数量 |
patience |
50 |
早停训练的等待轮次 |
batch |
16 |
每批图像数量(-1为自动批大小) |
imgsz |
640 |
输入图像的大小,以整数表示 |
save |
True |
保存训练检查点和预测结果 |
save_period |
-1 |
每x轮次保存检查点(如果<1则禁用) |
cache |
False |
True/ram, disk 或 False。使用缓存加载数据 |
device |
None |
运行设备,例如 cuda device=0 或 device=0,1,2,3 或 device=cpu |
workers |
8 |
数据加载的工作线程数(如果DDP则为每个RANK) |
project |
None |
项目名称 |
name |
None |
实验名称 |
exist_ok |
False |
是否覆盖现有实验 |
pretrained |
True |
(bool 或 str) 是否使用预训练模型(bool)或从中加载权重的模型(str) |
optimizer |
'auto' |
使用的优化器,选择范围=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto] |
verbose |
False |
是否打印详细输出 |
seed |
0 |
随机种子,用于可重复性 |
deterministic |
True |
是否启用确定性模式 |
single_cls |
False |
将多类数据作为单类训练 |
rect |
False |
矩形训练,每批为最小填充整合 |
cos_lr |
False |
使用余弦学习率调度器 |
close_mosaic |
10 |
(int) 最后轮次禁用马赛克增强(0为禁用) |
resume |
False |
从最后检查点恢复训练 |
amp |
True |
自动混合精度(AMP)训练,选择范围=[True, False] |
fraction |
1.0 |
训练的数据集比例(默认为1.0,即训练集中的所有图像) |
profile |
False |
在训练期间为记录器分析ONNX和TensorRT速度 |
freeze |
None |
(int 或 list, 可选) 在训练期间冻结前n层,或冻结层索引列表 |
lr0 |
0.01 |
初始学习率(例如 SGD=1E-2, Adam=1E-3) |
lrf |
0.01 |
最终学习率 (lr0 * lrf) |
momentum |
0.937 |
SGD动量/Adam beta1 |
weight_decay |
0.0005 |
优化器权重衰减5e-4 |
warmup_epochs |
3.0 |
热身轮次(小数ok) |
warmup_momentum |
0.8 |
热身初始动量 |
warmup_bias_lr |
0.1 |
热身初始偏差lr |
box |
7.5 |
框损失增益 |
cls |
0.5 |
cls损失增益(根据像素缩放) |
dfl |
1.5 |
dfl损失增益 |
pose |
12.0 |
姿态损失增益(仅限姿态) |
kobj |
2.0 |
关键点obj损失增益(仅限姿态) |
label_smoothing |
0.0 |
标签平滑(小数) |
nbs |
64 |
标称批大小 |
overlap_mask |
True |
训练期间掩码应重叠(仅限分割训练) |
mask_ratio |
4 |
掩码降采样比率(仅限分割训练) |
dropout |
0.0 |
使用dropout正则化(仅限分类训练) |
val |
True |
训练期间验证/测试 |
模型验证
前一小节中,我们使用了官方带有 128 张图片的 coco128.yaml 数据集进行训练,训练完成后,需要进行模型验证,以便在 coco128.yaml 数据集上验证训练过的模型的准确性。
此外,数据集也分为多种:
- 训练集(Training Set):用于训练和调整模型参数。
- 验证集(Validation Set):用于验证模型精度和调整模型参数。
- 测试集(Test Set):用于验证模型的泛化能力。
对于模型验证这一部分,官方文档的描述不多,同时本文作为入门文章,不会深入讲解这些细节,所以我们只需要记得自行训练的模型,都加上模型验证的代码模板即可。
在已经训练的模型中验证的模板如下:
from ultralytics import YOLO
# 加载训练后的模型
model = YOLO('detect/train3/weights/best.pt')
# 验证模型
metrics = model.val() # 无需参数,数据集和设置记忆
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # 包含每个类别的map50-95列表一般,在训练之后立即验证:
from ultralytics import YOLO
model = YOLO('yolov8n.pt') # 加载预训练模型(推荐用于训练)
# 训练模型
results = model.train(data='coco128.yaml', epochs=10, imgsz=640)
# 验证模型
metrics = model.val() # 无需参数,数据集和设置记忆
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
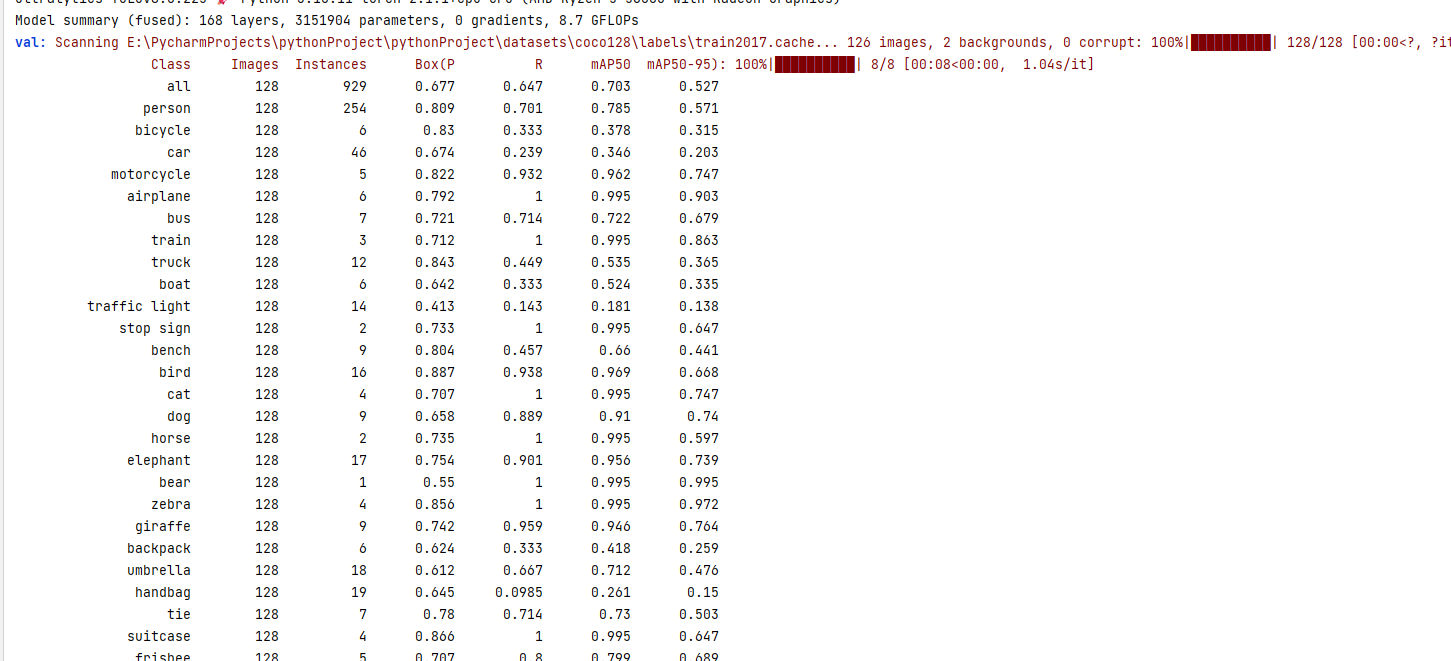
metrics.box.maps # 包含每个类别的map50-95列表验证结果:
前面提到过,coco128.yaml 数据集主要是人、动物和常见物体的图片,因此控制台列出了每种标记(person 人类、car 汽车等) 的识别验证结果。
当然,我们是入门阶段,这些信息对我们作用不大。
预测 & 识别
来到了激动人心的阶段,我们可以使用现有的模型或官方模型对图片进行识别。
你可以将下面两张图片下载保存:


下面两张图片,是代码识别后的结果,会自动将图片中识别到的物体标记名称以及使用矩形框选出来。


from ultralytics import YOLO
from PIL import Image
# 加载训练后的模型
model = YOLO('detect/train3/weights/best.pt')
# 导入并识别图片,results 是处理后的结果
results = model(['img1.jpg', 'img2.jpg'])
# 保存处理后的图片到目录中
i = 0
for r in results:
i += 1
im_array = r.plot() # 绘制包含预测结果的BGR numpy数组
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL图像
im.save('results/' + str(i) + '.jpg') # 保存图像当然,我们也可以在处理图片之前预览图片:
im.show() # 弹出窗口,预览图像
im.save('results/' + str(i) + '.jpg') # 保存图像如果只需要获取识别信息,不需要处理图片,那么可以这样打印信息:
from ultralytics import YOLO
from PIL import Image
# 加载训练后的模型
model = YOLO('detect/train3/weights/best.pt')
# 导入并识别图片,results 是处理后的结果
results = model(['img1.jpg', 'img2.jpg'])
# 处理结果列表
for result in results:
boxes = result.boxes # 边界框输出的 Boxes 对象
masks = result.masks # 分割掩码输出的 Masks 对象
keypoints = result.keypoints # 姿态输出的 Keypoints 对象
probs = result.probs # 分类输出的 Probs 对象
print("图片边框")
print(boxes)
print("分割掩码")
print(masks)
print("姿势输出")
print(keypoints)
print("分类输出")
print(probs)注意,上面的结果除了边框有值,其它都是 None,因为我们只识别图片,并没有做分类、切割、姿势识别等。
前面提到,results 是处理之后的结果,results 是一个 Results 对象,Results 对象具有的属性如下:
| 属性 | 类型 | 描述 |
|---|---|---|
orig_img |
numpy.ndarray |
原始图像的numpy数组。 |
orig_shape |
tuple |
原始图像的形状,格式为(高度,宽度)。 |
boxes |
Boxes, 可选 |
包含检测边界框的Boxes对象。 |
masks |
Masks, 可选 |
包含检测掩码的Masks对象。 |
probs |
Probs, 可选 |
包含每个类别的概率的Probs对象,用于分类任务。 |
keypoints |
Keypoints, 可选 |
包含每个对象检测到的关键点的Keypoints对象。 |
speed |
dict |
以毫秒为单位的每张图片的预处理、推理和后处理速度的字典。 |
names |
dict |
类别名称的字典。 |
path |
str |
图像文件的路径。 |
Results具有以下方法:
| 方法 | 返回类型 | 描述 |
|---|---|---|
__getitem__() |
Results |
返回指定索引的Results对象。 |
__len__() |
int |
返回Results对象中的检测数量。 |
update() |
None |
更新Results对象的boxes, masks和probs属性。 |
cpu() |
Results |
将所有张量移动到CPU内存上的Results对象的副本。 |
numpy() |
Results |
将所有张量转换为numpy数组的Results对象的副本。 |
cuda() |
Results |
将所有张量移动到GPU内存上的Results对象的副本。 |
to() |
Results |
返回将张量移动到指定设备和dtype的Results对象的副本。 |
new() |
Results |
返回一个带有相同图像、路径和名称的新Results对象。 |
keys() |
List[str] |
返回非空属性名称的列表。 |
plot() |
numpy.ndarray |
绘制检测结果。返回带有注释的图像的numpy数组。 |
verbose() |
str |
返回每个任务的日志字符串。 |
save_txt() |
None |
将预测保存到txt文件中。 |
save_crop() |
None |
将裁剪的预测保存到save_dir/cls/file_name.jpg。 |
tojson() |
None |
将对象转换为JSON格式。 |
除了本地图片外,ultralytics 还支持视频流,可以从本地或网络中导入要识别的资源。对于视频流的处理,本文的后续章节再介绍。
ultralytics 支持识别的其它资源:
| 来源 | 参数 | 类型 | 备注 |
|---|---|---|---|
| image | 'image.jpg' |
str 或 Path |
单个图像文件。 |
| URL | 'https://ultralytics.com/images/bus.jpg' |
str |
图像的 URL 地址。 |
| screenshot | 'screen' |
str |
截取屏幕图像。 |
| PIL | Image.open('im.jpg') |
PIL.Image |
RGB 通道的 HWC 格式图像。 |
| OpenCV | cv2.imread('im.jpg') |
np.ndarray |
BGR 通道的 HWC 格式图像 uint8 (0-255)。 |
| numpy | np.zeros((640,1280,3)) |
np.ndarray |
BGR 通道的 HWC 格式图像 uint8 (0-255)。 |
| torch | torch.zeros(16,3,320,640) |
torch.Tensor |
RGB 通道的 BCHW 格式图像 float32 (0.0-1.0)。 |
| CSV | 'sources.csv' |
str 或 Path |
包含图像、视频或目录路径的 CSV 文件。 |
| video✅ | 'video.mp4' |
str 或 Path |
如 MP4, AVI 等格式的视频文件。 |
| directory✅ | 'path/' |
str 或 Path |
包含图像或视频文件的目录路径。 |
| glob ✅ | 'path/*.jpg' |
str |
匹配多个文件的通配符模式。使用 * 字符作为通配符。 |
| YouTube ✅ | 'https://youtu.be/LNwODJXcvt4' |
str |
YouTube 视频的 URL 地址。 |
| stream ✅ | 'rtsp://example.com/media.mp4' |
str |
RTSP, RTMP, TCP 或 IP 地址等流协议的 URL 地址。 |
| multi-stream✅ | 'list.streams' |
str 或 Path |
一个流 URL 每行的 *.streams 文本文件,例如 8 个流将以 8 的批处理大小运行。 |
如果要了解每种资源的导入方式,可以打开 https://docs.ultralytics.com/zh/modes/predict/#_4
本文不再赘述所有导入方式,不过本文后续会介绍视频流等资源识别。
导出
ultralytics 支持将训练后的模型导出为 ONNX、 TensorRT、 CoreML 等格式,然后我们可以使用其它框架或其它语言进行调用,例如 C# 的 ML.NET 框架。
from ultralytics import YOLO
# 加载模型 .pt 文件模型
model = YOLO('path/to/best.pt')
# 导出为其它类型的模型
model.export(format='onnx')导出为其它模型时,需要安装对应支持包,如果本地没有安装过,则第一次会自动安装。
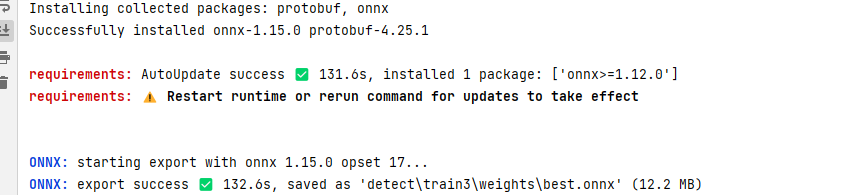
代码执行后,控制台会打印出模型文件被导出到哪个位置:
ultralytics 支持将模型导出为以下格式:
| 格式 | format 参数 |
模型 | 元数据 | 参数 |
|---|---|---|---|---|
| PyTorch | - | yolov8n.pt |
✅ | - |
| TorchScript | torchscript |
yolov8n.torchscript |
✅ | imgsz, optimize |
| ONNX | onnx |
yolov8n.onnx |
✅ | imgsz, half, dynamic, simplify, opset |
| OpenVINO | openvino |
yolov8n_openvino_model/ |
✅ | imgsz, half |
| TensorRT | engine |
yolov8n.engine |
✅ | imgsz, half, dynamic, simplify, workspace |
| CoreML | coreml |
yolov8n.mlpackage |
✅ | imgsz, half, int8, nms |
| TF SavedModel | saved_model |
yolov8n_saved_model/ |
✅ | imgsz, keras |
| TF GraphDef | pb |
yolov8n.pb |
❌ | imgsz |
| TF Lite | tflite |
yolov8n.tflite |
✅ | imgsz, half, int8 |
| TF Edge TPU | edgetpu |
yolov8n_edgetpu.tflite |
✅ | imgsz |
| TF.js | tfjs |
yolov8n_web_model/ |
✅ | imgsz |
| PaddlePaddle | paddle |
yolov8n_paddle_model/ |
✅ | imgsz |
| ncnn | ncnn |
yolov8n_ncnn_model/ |
✅ | imgsz, half |
追踪
Ultralytics 的追踪可以处理视频中的物体。前面笔者已经介绍了通过图片进行物体识别,其实还支持对图片进行姿势识别、图片分类、将物体从图片中切割出来,这些等后面的章节再介绍。Ultralytics 的追踪也支持物体识别、姿势识别等,在本节中,笔者将介绍如何在视频中识别和追踪物体,在后面的章节中会介绍更多的示例。
Ultralytics YOLO 扩展了其物体检测功能,以提供强大且多功能的物体追踪:
- 实时追踪: 在高帧率视频中无缝追踪物体。
- 支持多个追踪器: 从多种成熟的追踪算法中选择。
- 自定义追踪器配置: 通过调整各种参数来定制追踪算法,以满足特定需求。
Ultralytics 默认有两种追踪器。
- BoT-SORT - 模型文件为
botsort.yaml,默认使用,不需要配置。 - ByteTrack - 模型文件为
bytetrack.yaml。
以下代码演示了使用 cv2 加载视频文件,并逐帧识别图片中的物体,然后每识别一帧,就显示到桌面中。
from ultralytics import YOLO
import cv2
# 加载自己训练的物体识别模型
model = YOLO('detect/train3/weights/best.pt')
# 或者使用官方训练的物体识别模型
# model = YOLO('yolov8n.pt')
# 使用 cv2 加载视频文件
video_path = "1.mp4"
cap = cv2.VideoCapture(video_path)
# 循环遍历视频帧
while cap.isOpened():
# 从视频读取一帧
success, frame = cap.read()
if success:
# 在帧上运行YOLOv8追踪,持续追踪帧间的物体
results = model.track(frame, persist=True)
# 在帧上展示结果
annotated_frame = results[0].plot()
# 使用 cv2 弹出窗口,并展示带注释的帧
# 也就是一边识别,一边播放视频
cv2.imshow("YOLOv8 Tracking", annotated_frame)
# 如果按下'q'则退出循环
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# 如果视频结束则退出循环
break
# 释放视频捕获对象并关闭显示窗口
cap.release()
cv2.destroyAllWindows()
当然,由于笔者下载的视频比较模糊,以及训练的数据集不大,识别出来的物体名称不是很理想,不过其追踪器确实确实牛批。
图像分割提取
图像分割用于在识别图片中的物体后,将物体从图片中提取出来。
示例代码如下:
from ultralytics import YOLO
# 加载 yolov8n-seg 模型
model = YOLO('yolov8n-seg.pt')
# 训练模型
# results = model.train(data='coco128-seg.yaml', epochs=100, imgsz=640)
# 验证
# ... ...
# 对图像进行处理
results = model(['img1.jpg', 'img2.jpg'])
# 保存处理后的图片到目录中
i = 0
for r in results:
i += 1
im_array = r.save_crop(save_dir="results")提取到的物体图片会被存储到:
如果不需要提取物体,由于 ultralytics 会先创建图片蒙版,因此我们可以导出带有物体蒙版的图片。
from ultralytics import YOLO
from PIL import Image
# 加载 yolov8n-seg 模型
model = YOLO('yolov8n-seg.pt')
# 训练模型
# results = model.train(data='coco128-seg.yaml', epochs=100, imgsz=640)
# 验证
# ... ...
# 对图像进行处理
results = model(['img1.jpg', 'img2.jpg'])
# 保存处理后的图片到目录中
i = 0
for r in results:
i += 1
im_array = r.plot() # 绘制包含预测结果的BGR numpy数组
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL图像
im.save('results/' + str(i) + '.jpg') # 保存图像
分类
很明显,用于分类图片。
分类图片需要使用官方的 yolov8n-cls.pt 模型。
官方提供了一个 mnist160 数据集,该数据集是从 0-9 的手写图片,因此我们训练模型之后,也是用来做手写数字识别的。
这里随便写三个数字:

由于数据量不大,因此我们可以直接训练然后使用训练后的模型提取图片中的文字:
from ultralytics import YOLO
# 加载 yolov8n-cls 模型
model = YOLO('yolov8n-cls.pt')
# 训练模型
results = model.train(data='mnist160', epochs=100, imgsz=64)
# 验证
# ... ...
# 对图像进行处理
results = model(['666.png'])
# 保存处理后的图片到目录中
i = 0
for r in results:
r.save_txt(txt_file="results/cls"+ str(i) + '.txt')
i += 1因为训练的数据集是单数字的,因此对多数字的支持有点问题。
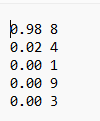
改成大大的 6 ,再次识别:

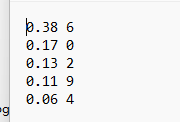
姿势识别
姿势识别用于在图片或视频中给人体进行打点、划线,然后追踪人体的姿势变化。

示例代码如下:
import cv2
from ultralytics import YOLO
# 加载 yolov8n-pose 模型,并进行训练
model = YOLO('yolov8n-pose.pt')
results = model.train(data='coco8-pose.yaml', epochs=10, imgsz=640)
# 打开视频文件
video_path = "1.mp4"
cap = cv2.VideoCapture(video_path)
# 循环遍历视频帧
while cap.isOpened():
# 从视频读取一帧
success, frame = cap.read()
if success:
# 在帧上运行YOLOv8追踪,持续追踪帧间的物体
results = model.track(frame, persist=True)
# 在帧上展示结果
annotated_frame = results[0].plot()
# 展示带注释的帧
cv2.imshow("YOLOv8 Tracking", annotated_frame)
# 如果按下'q'则退出循环
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# 如果视频结束则退出循环
break
# 释放视频捕获对象并关闭显示窗口
cap.release()
cv2.destroyAllWindows()轨迹生成
在视频中识别追踪物体时,还可以对物体的运行轨迹进行追踪。
手头上没有更多视频演示,将就一下。

示例代码如下:
from collections import defaultdict
import cv2
import numpy as np
from ultralytics import YOLO
# 加载 yolov8n.pt 模型,也可以使用其它模型
model = YOLO('yolov8n.pt')
# 打开视频
video_path = "0.mp4"
cap = cv2.VideoCapture(video_path)
# 保存历史记录
track_history = defaultdict(lambda: [])
# 处理视频的每一帧
while cap.isOpened():
success, frame = cap.read()
if success:
# 追踪
results = model.track(frame, persist=True)
# 读取当前帧中物体的框
boxes = results[0].boxes.xywh.cpu()
# 如果未识别到图像有框时,则忽略
if results[0].boxes.id is None:
continue
# 获取每个被追踪的物体 id
track_ids = results[0].boxes.id.int().cpu().tolist()
annotated_frame = results[0].plot()
# 绘制
for box, track_id in zip(boxes, track_ids):
x, y, w, h = box
track = track_history[track_id]
track.append((float(x), float(y)))
if len(track) > 30:
track.pop(0)
points = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))
cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)
cv2.imshow("YOLOv8 Tracking", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
break
cap.release()
cv2.destroyAllWindows()

文章评论
你好,这个项目可以分享一下吗,刚开始学习,感觉比官网的详细实用多了
@awe demo 示例和资源文件地址:https://github.com/whuanle/yolo8_demo
yolo8企业是可以直接用的,只需将相关代码向服务的用户开源
@admin 代价有点 “大”
@痴者工良 企业可以直接用于商业用途,只需遵循AGPL-3.0协议就行。
如果不想遵循这个协议,可以去申请许可。见网站原文:
Designed for commercial use, this license permits seamless integration of Ultralytics software and AI models into commercial goods and services, bypassing the open-source requirements of AGPL-3.0.
If your scenario involves leveraging our models for a commercial use case, please complete the request form and we will be in touch!